


Imagínese el escenario: 75.000 documentos y toneladas de noticias, investigaciones y mensajes de chat para filtrar, etiquetar y categorizar sin un patrón discernible en su secuencia. Desea ordenarlos por compañía y por ubicación, pero sin las etiquetas de nivel superior, por página y por oración, la tarea parece casi imposible. ¿Es el documento 14.198º un informe macroeconómico sobre América del Norte, China, Tokio o la interacción de los tres? ¿El documento 47.938 discutir dividendos, ganancias o el lanzamiento de un nuevo producto? ¿Ese correo electrónico de cliente de hace 6 meses hace referencia a Google, Alphabet o GOOG? Peor aún, algunos conjuntos de texto pueden tener cientos de páginas y contener muchos temas diferentes y datos importantes. Los títulos, las tablas de contenido y las etiquetas de nivel superior solo pueden decirle algo.
usted podría contrate a personas para que lean, comprendan y organicen todos los documentos, correos electrónicos, noticias y mensajes de chat manualmente. Desafortunadamente, esto consume una gran cantidad de tiempo y recursos financieros, y con los registros de chat, correos electrónicos, artículos de noticias e informes que crecen cada día, puede ser imposible indexar todo el contenido usando los ojos y la mente humanos de todos modos. Los mensajes entre empleados de un departamento podrían resultar muy útiles para los de otro, pero la mayoría de las empresas dejan que estos datos desaparezcan en las bandejas de entrada de los empleados, donde su potencial de apalancamiento se pierde en el vacío.
Una mejor solucion es impulsado por el aprendizaje automático sistemas de comprensión del lenguaje natural (NLU), que automatizan la encontrar, identificar y etiquetar proceso, resultando en "entidades etiquetadas" o "entidades extraídas". NLU es un enfoque más amplio del procesamiento tradicional del lenguaje natural (NLP), que intenta comprender las variaciones en el texto como si representaran la misma información semántica (significado). Con las entidades extraídas hasta el nivel de la oración, uno puede realizar todo tipo de analítica de texto, como mapas de calor y agrupaciones que conducen a conocimientos. El análisis de sentimientos es otra analítica textual muy popular que se utiliza para comprender grandes corpus (conjuntos agregados) de texto.
En CityFALCON, acabamos de lanzar un sistema de extracción de entidades de NLU y un análisis de opiniones ajustado específicamente para contenido comercial, financiero y político en varios idiomas para entidades identificadas y para documentos completos, noticias, registros de chat y cadenas de correo electrónico.
La necesidad
Hay varias razones para identificar y etiquetar productos, empresas, personas y otros temas en el texto. Una de las razones es que los gobiernos tienen requisitos de retención de documentos y algunas empresas tienen conjuntos muy grandes de documentos retenidos que no están organizados ni se utilizan para un análisis posterior de Big Data.
Otras empresas simplemente conservan todos sus mensajes y documentos internos para referencia futura o para análisis de Big Data más adelante. Si el texto se genera internamente, tal vez tengan algunas etiquetas, pero no describen el contenido en su interior con mucha profundidad. Si el texto se crea externamente, como contenido de noticias, las etiquetas pueden ser insuficientes, inexactas o inexistentes.
Independientemente del caso, solo se puede obtener una comprensión limitada de un texto a partir de etiquetas de nivel superior, títulos de secciones y resúmenes de secciones. Los metadatos existen a través de todas las capas de un texto, y NLU puede ayudar a comprender mejor los documentos individuales y todo un corpus. Dado que NLU funciona de manera tan granular como el nivel de oración, los documentos se pueden analizar algorítmicamente por oración y la salida se puede procesar para obtener una visión poderosa.
Una de las promesas de Big Data es procesar cantidades de información que los humanos individuales o equipos de ellos simplemente no podrían. Debido a que nuestras mentes humanas solo pueden contener cierta cantidad de información a la vez, y la comunicación entre humanos está limitada por la rapidez con la que podemos transferir pensamientos a través del lenguaje, comprender tres millones de páginas de noticias, documentación y correos electrónicos no es una hazaña para un humano. o incluso un equipo. Es para que las máquinas destilen en trozos mucho más manejables.
NLU y los análisis asociados ayudan a las empresas a organizar su contenido, hacer que se pueda buscar más rápidamente con palabras clave y pueden ofrecer información que las mentes humanas simplemente no pueden sintetizar (aunque podemos comprender el resultado, por supuesto).
Por lo tanto, siempre que sea necesario organizar, categorizar y comprender grandes volúmenes de información textual en alta resolución, el sistema NLU de CityFALCON puede proporcionar información y análisis entre departamentos con facilidad.
Cómo funciona
En un nivel alto, nuestra API recién lanzada desglosa cualquier conjunto de texto en sus oraciones constituyentes y luego identifica todos los entidades en cada oración. Por ejemplo, tomemos un título reciente:
Los futuros de acciones caen después de las ganancias, la amenaza de Trump para los aranceles de China sobre la pandemia
Que nuestros sistemas se dividirán así:
Acciones = instrumento financiero
Futuros = instrumento financiero
Ganancias = evento
Trump = persona
China = ubicación
Tarifas = tema_financiero
Pandemia = tema_financiero
Y si desea ver la respuesta JSON completa, la hemos publicado aquí para usted.
{"Text": "Los futuros de acciones caen después de las ganancias, la amenaza de Trump para los aranceles de China sobre la pandemia",
"Lang": "en",
"Etiquetas": [
{
"Inicio": 0,
"Fin": 5,
"Valor": "Stock",
"Tipo": "instrumento_financiero",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Acciones",
"Type": "topic_classes",
"Metadatos": {}
}
]
},
{
"Inicio": 6,
"Fin": 13,
"Valor": "futuros",
"Tipo": "instrumento_financiero",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Futuros",
"Tipo": "temas_financieros",
"Metadatos": {}
}
]
},
{
"Inicio": 25,
"Fin": 33,
"Valor": "ganancias",
"Tipo": "evento",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Ingresos",
"Type": "major_business_and_related_activities",
"Metadatos": {}
}
]
},
{
"Inicio": 36,
"Fin": 43,
"Valor": "Trump",
"Tipo": "persona",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Familia Trump",
"Tipo": "personas",
"Metadatos": {}
}
]
},
{
"Inicio": 55,
"Fin": 60,
"Valor": "China",
"Tipo": "ubicación",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "China",
"Tipo": "geo_regiones",
"Metadatos": {
"países": [
"China"
],
"Subcontinentes": [
"Asia Oriental"
],
"Continentes": [
"Asia"
]
}
}
]
},
{
"Inicio": 61,
"Fin": 68,
"Valor": "tarifas",
"Tipo": "tema_financiero",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Tarifas",
"Tipo": "temas_financieros",
"Metadatos": {}
}
]
},
{
"Inicio": 74,
"Fin": 82,
"Valor": "pandemia",
"Tipo": "tema_financiero",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Pandemia",
"Tipo": "otros_temas",
"Metadatos": {}
}
]
}
]
}
Además, tome la entidad China. Debido a que fue "emparejado" en nuestra base de datos, también tiene una jerarquía asociada. Esto significa el término China ahora también se puede devolver cuando alguien busca en Asia Oriental o Asia, lo que permite una mejor indexación del contenido interno.
Además de las jerarquías, las entidades emparejadas pueden agrupar varios nombres. Un ejemplo de ello es el término "Coronavirus", que se comparará en nuestros sistemas con "COVID-19", "covid19" y "covid", entre muchas otras palabras y frases cortas relacionadas. Esto permite que un empleado busque un solo término y reciba cualquier elemento relacionado, incluso si una búsqueda de texto simple falla, porque la búsqueda de texto simple COVID-19 no devolverá menciones de Coronavirus.
Veamos otro ejemplo. Este podría ser un mensaje de chat entre empleados:
- ¿Crees que Estados Unidos iniciará una investigación contra Facebook?
Nuevamente, aquí está el JSON devuelto por nuestros sistemas.
{
"Texto": "cree que Estados Unidos iniciará una investigación contra Facebook",
"Lang": "en",
"Etiquetas": [
{
"Inicio": 14,
"Fin": 16,
"Valor": "EE. UU.",
"Tipo": "ubicación",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Estados Unidos de América",
"Tipo": "geo_regiones",
"Metadatos": {
"países": [
"Estados Unidos de America"
],
"Subcontinentes": [
"América del Norte"
],
"Continentes": [
"Norteamérica"
]
}
}
]
},
{
"Inicio": 51,
"Fin": 59,
"Valor": "Facebook",
"Tipo": "empresa",
"Coincidente": verdadero,
"Entidades": [
{
"Nombre": "Facebook Inc",
"Tipo": "acciones",
"Metadatos": {
"Legal_ids": [
"0201665019_irs-us",
"0001326801_sec-us"
],
"Tickers": [
"FB_US"
],
"Categorías": [
"Redes sociales"
],
"Subindustrias": [
"Servicios e infraestructura de Internet"
],
"Industrias": [
"Servicios de TI"
],
"Sectores": [
"Tecnología",
"Comunicaciones"
]
}
}
]
},
{
"Inicio": 22,
"Fin": 42,
"Valor": "iniciar investigación",
"Tipo": "evento",
"Coincidente": falso
}
]
}
Aquí, "EE.UU." es una entidad coincidente y también contiene una jerarquía. El tema específico Estados Unidos de America será identificable con "los EE. UU.", "Estados Unidos" y "América", y también se puede encontrar cuando alguien busque en América del Norte. Por lo tanto, cuando un empleado recuerda vagamente el hilo de la conversación sobre "América", no se sentirá frustrado por la falta de coincidencia entre su término de búsqueda, "América", y el término real utilizado, "EE.UU." En una búsqueda de texto normal, el intento de encontrar la conversación puede fallar.
Las empresas también forman parte de una jerarquía en la economía, y la búsqueda de servicios de TI garantizará que “Facebook” también se incluya en los resultados. No solo eso, sino que debido a que Facebook es una empresa pública, se devuelven sus números de identidad legal, incluido su identificador SEC y ticker (s) por país. Esto podría estar conectado a los archivos de la empresa o alimentarse mediante programación a otro algoritmo que recupera SEC presentaciones de CityFALCON o utilizarse para hacer referencias cruzadas en casos judiciales en el sistema judicial de EE. UU.
Por último, también puede resultar útil seleccionar acciones de cualquier conversación o informe de investigación. El fraseo iniciar investigación fue recogido por nuestro aprendizaje automático sistemas como evento. Estos datos ayudan a determinar el tema de un texto, y un buen caso de uso sería marcar los correos electrónicos con sus eventos. En este ejemplo, el evento fue no coinciden, pero hay decenas de miles de eventos en CityFALCON que coinciden de la misma manera que las ubicaciones y las empresas se pueden emparejar con los datos asociados.
Dado que a las máquinas no les importa si tiene 1 o 100.000 oraciones, este mismo proceso se puede repetir indefinidamente para cualquier tamaño de corpus. Todo esto se procesará en unos segundos con nuestro algoritmo procesándolo en una GPU rápida.
El alcance del sistema CityFALCON
Identificamos 20 grupos de entidades personalizadas y más de 300,000 temas de "entidades nombradas" que son específicos de finanzas, agregando una capa profunda de análisis posible para bancos, gobiernos, academia y otros usuarios que necesitan un análisis de contenido basado en términos económicos y financieros, yendo más allá de los productos de competidores como IBM o Microsoft, cuyos sistemas están diseñados para contenido general.
Por ejemplo, un solo tema cubre la idea de "Estados Unidos de América", donde los nombres asociados, como "EE. UU.", "América" y "EE. UU." Se consideran parte de ese tema, al igual que los metadatos (para ubicaciones (esta es la jerarquía geográfica). Todos los temas vienen con información asociada y, si está disponible, jerarquías y nombres asociados. Van desde ubicaciones hasta personas, empresas y productos, e incluso puede navegar por ellos en nuestro Directorio si quieres verlos todos. A través de la API, podrá indexar su propio contenido de la misma manera, y esta capacidad es una gran reserva de poder organizativo.
Con todos estos temas y grupos de entidades, NLU como herramienta cognitiva transforma la búsqueda de un instrumento que fortalece una idea ya presente en la mente en un instrumento que construye ideas a partir de conceptos. En lugar de buscar un documento específico o una cadena de correo electrónico Biotecnología, los trabajadores pueden buscar etiquetas de sector. Quizás se menciona comúnmente otro sector junto con la biotecnología, que sirve como una vía de conocimiento potencial. Por el contrario, uno podría desear encontrar todos los movimientos de precios en una cadena de correo electrónico o un conjunto de 15.000 noticias, independientemente de la dirección y el vocabulario específico utilizado (oleada, espiga, salto, cohete, disparar, etc.).
En el momento de la publicación de esta publicación de blog, los sistemas CityFALCON están listos para aceptar contenido en inglés y ruso. El ucraniano y el español serán aceptados este verano, y se agregarán otros idiomas a medida que nuestros sistemas se desarrollen a través de nuestro Proyecto de I + D + i en marcha en Malta, que incluye mandarín, japonés, coreano, alemán, francés, portugués y otros. Con el tiempo, cubriremos más de 90 idiomas.
NLU para contenido interno
El núcleo de CityFALCON es NLU: recopilamos, agregamos y procesamos noticias y contenido financiero, entendemos su idioma, y lo entregamos a los usuarios en tiempo real. Agregamos algunos análisis en la parte superior, como un puntaje de relevancia, sentimiento y algunas otras ideas en desarrollo.
Este enorme motor de comprensión del lenguaje principalmente financiero y económico funciona bien para todos los datos que obtenemos nosotros mismos. Funcionará igual de bien con los datos de texto del cliente, ya sea investigaciones patentadas, informes económicos, transcripciones de llamadas de ganancias o simples informes internos memorandos y correos electrónicos.
Nuestro motor NLU patentado está listo para que los clientes lo usen para indexar y organizar su propio contenido. El motor NLU ha sido perfeccionado por nuestro equipo de analistas financieros y de NLU durante los últimos tres años en artículos de noticias, tweets y presentaciones regulatorias. Ahora ese poder se puede aplicar al contenido financiero interno que le gustaría indexar.
Un portal de empleados potenciales puede mostrar los siguientes componentes.
Contenido externo
Proporcionamos este contenido de nuestras más de 5000 fuentes y Twitter. Le enviaremos noticias, tweets, estados financieros y presentaciones regulatorias, un puntaje de relevancia de CityFALCON, datos de contenido externo de NLU y análisis de sentimientos.
Contenido interno
Esto proviene de cualquier texto proporcionado por el cliente, como correspondencia interna, publicaciones y correo electrónico informal entre departamentos.
Contenido interorganizacional
Algunas de las etiquetas devueltas contienen no solo nombres, sino también información importante como posición en jerarquías económicas, como sectores y subindustrias, además de información legal como números de identificación de empresas y tickers. Estos pueden potenciar aún más su búsqueda o automatizar algunos procesos, como obtener la última cotización de acciones de un intercambio para sus operadores.
Chat en tiempo real
Las conversaciones de los empleados se etiquetan a medida que ocurren, lo que proporciona información que se puede buscar, como la frecuencia con la que un equipo menciona un sector o una persona clave durante una semana laboral. Esto permite a los responsables de la toma de decisiones descubrir información útil que de otro modo estaría oculta. Si todo el mundo está charlando sobre X, entonces X podría ser el próximo gran movimiento en los mercados.
Esto también permite a los empleados mirar a través de hilos de chat anteriores y buscar por entidad o grupo de entidad en lugar de una palabra clave específica, ampliando el potencial para hacer conexiones. Por ejemplo, alguien podría querer conocer todas las instancias de un compañero de trabajo específico que menciona "instrumento_financiero" o "empresa", independientemente de los detalles.
El chat en tiempo real podría incluso generar una fuente de noticias en tiempo real que se adapte al tema actual de la conversación.
Visualizaciones
Este componente permite comprender la estructura y los temas de un conjunto de textos de un vistazo, ya sean hilos de correo electrónico con clientes, noticias de la semana o actas de reuniones. La disposición y el diseño deberán implementarse por parte de la empresa, pero CityFALCON puede proporcionar datos estructurados de NLU como base de este componente.
Sólo un ejemplo de un análisis ad-hoc de la fuerza de una tendencia podría visualizarse en la fuerza de las palabras empleadas. Si todos los titulares dicen “bajar”, “luchar” y “flotar más abajo”, sabrá que la situación no es tan mala como si todos estuvieran diciendo “zambullirse”, “implosionar” y “diezmar”. Al utilizar CityFALCON NLU, este tipo de análisis sobre la marcha se vuelve tan simple como mirar todas las instancias de un price_movement etiqueta en un conjunto de textos.
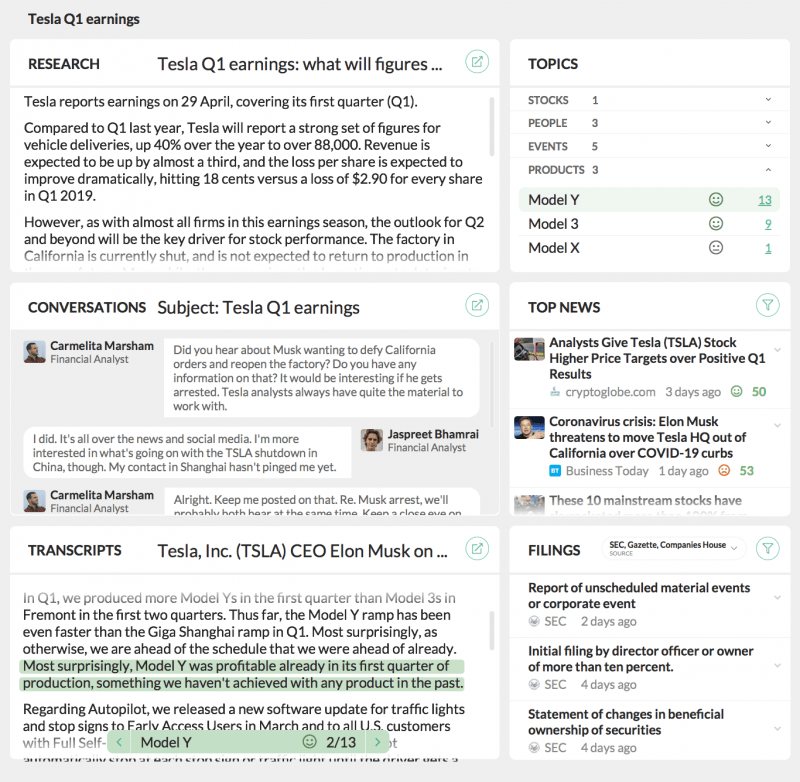
Un panel de empleados potencial de contenido interno y externo
¿Por qué pagar el servicio?
Algunos pueden argumentar que construir estos sistemas por sí mismos es fácil o requiere pocos recursos. Algunos pueden intentar subcontratar el etiquetado y la organización a mano de obra barata en el extranjero, mientras que otros pueden intentar contratar a algunos desarrolladores para que lo hagan internamente. Sin embargo, ninguna de estas soluciones resuelve adecuadamente el problema y se pierden un valor agregado muy importante.
Primero, es posible que los humanos no puedan procesar el gran volumen de contenido, por lo que el procesamiento manual no es aplicable. Además, no es posible aplicar la extracción manual de NLU a los chats y otras fuentes que cambian constantemente en tiempo real. Es posible con aprendizaje automático y sistemas automatizados.
En segundo lugar, estos sistemas tardan mucho en construirse e implementarse. Los algoritmos no solo necesitan entrenamiento, también necesitan ser probados y ajustados. El sistema completo puede tardar años en construirse, mientras que es posible licenciar la tecnología ahora mismo.
En tercer lugar, la "comprensión" y la estructura subyacentes de todo el aparato deben adaptarse a medida que surgen nuevas ideas y conceptos en el mundo. En los negocios y la política, constantemente hay nuevas personas, empresas, leyes y eventos que deben ser rastreados. Necesitaría un equipo completo para rastrear todo esto y actualizar los algoritmos en consecuencia; afortunadamente, CityFALCON ya lo hace por usted con nuestro equipo de analistas financieros multilingües.
¿Se pueden construir y mantener estos sistemas internamente? Si. Sin embargo, su construcción y mantenimiento posterior rápidamente se vuelven costosos y requieren mucho tiempo, especialmente en áreas de rápida evolución como las finanzas, los negocios y la política. CityFALCON puede manejar los detalles técnicos. Te enfocas en el cliente y el negocio.
En última instancia, el valor reside en los datos. Con el producto de CityFALCON, el valor latente se puede extraer de fuentes de texto financieras y económicas y canalizarlo hacia actividades generadoras de ingresos como el comercio y la gestión de carteras. Podemos ayudarlo a enriquecer sus metadatos hasta las palabras en oraciones, conectar entidades individuales con información asociada y construir conexiones similares a la web entre todas las partes de su negocio.
Seguridad y confidencialidad
Dado que la seguridad y la confidencialidad son primordiales cuando se trata de documentación interna o correspondencia privada entre clientes y empleados, nuestro sistema garantiza que sus datos estén en buenas manos.
Evitando los detalles técnicos, todo el texto que envíe se enviará a través de un túnel cifrado HTTPS normal, por lo que nadie podrá leer los datos de la solicitud que envíe. Luego, en nuestros servidores, sus datos residen temporalmente en la RAM mientras se procesan. Una vez que se procesa, todos los rastros de sus datos desaparecen de nuestro sistema. Esto significa que el texto nunca se escribe en el disco ni se almacena en nuestra base de datos.
Si alguien piratea nuestros sistemas o un empleado deshonesto intenta vender información del cliente, no hay datos que robar. El contenido pasado se ha borrado irremediablemente. El único inconveniente es que su solicitud no se almacena en caché, por lo que si necesita volver a extraer del mismo conjunto de texto, tal vez se eliminó accidentalmente en una computadora interna, deberá volver a transmitirlo. Sin embargo, la necesidad de volver a procesar un documento es bastante rara.
Por el contrario, para aquellos que realmente quieren mantener las cosas locales, podemos ofrecer una implementación de sistema local con actualizaciones periódicas, por lo que todo el proceso de NLU puede ocurrir en el sitio del cliente, sin que los datos salgan de sus propios sistemas.
Integración conveniente
Con nuestra API, cualquier empresa ahora puede indexar su contenido interno de la documentación anterior o en tiempo real. Es tan simple como consultar el punto final de la API para la extracción de entidades (etiquetado NLU) y autorizarse con la clave única de su empresa. Por supuesto, deberá crear su propio panel e interfaz para sus propios usuarios, pero nosotros nos encargaremos de todo el trabajo pesado.ng en NLU: este es el servicio que brindamos, después de todo.
Contáctenos para configurar una demostración y discutir posibles casos de uso, límites de llamadas y cualquier otra pregunta que pueda tener.
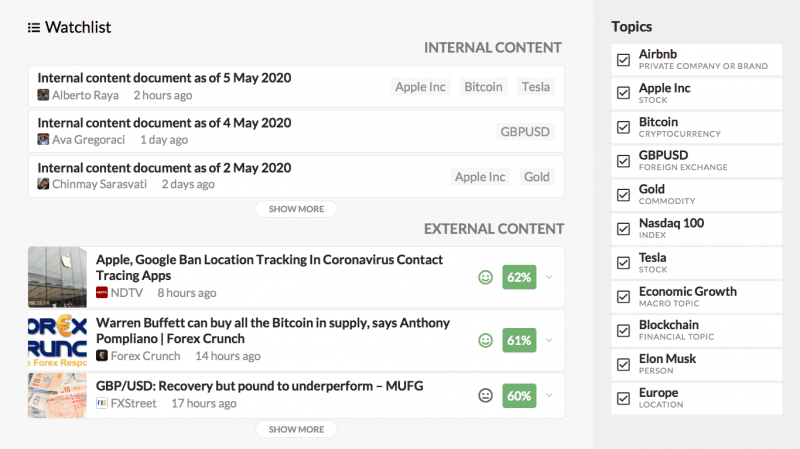
Una vista interna más simple con una lista de seguimiento asociada
Deja una respuesta