


Imaginez le scénario: 75 000 documents et des tonnes de messages d'actualité, de recherche et de discussion à passer au crible, étiqueter et classer sans motif perceptible dans leur séquence. Vous voulez les trier par entreprise et par emplacement, mais sans les balises de niveau supérieur, par page et par phrase, la tâche semble presque impossible. Le 14 198e document est-il un rapport macroéconomique sur l'Amérique du Nord, la Chine, Tokyo, ou l'interaction des trois? Le 47 938e document discuter des dividendes, des bénéfices ou du lancement d'un nouveau produit? Cet e-mail client datant de 6 mois fait-il référence à Google, Alphabet ou GOOG? Pire encore, certains ensembles de texte peuvent faire des centaines de pages et contenir de nombreux sujets différents et des éléments de données importantes. Les titres, les tables des matières et les balises de premier niveau ne peuvent vous en dire plus.
Toi pourrait embauchez des personnes pour lire, comprendre et organiser manuellement chaque document, e-mail, actualité et message de discussion. Malheureusement, cela consomme beaucoup de temps et de ressources financières, et avec les journaux de discussion, les courriels, les articles de presse et les rapports qui augmentent chaque jour, il peut être impossible d'indexer réellement tout le contenu en utilisant les yeux et l'esprit humains de toute façon. Les messages entre les employés d'un service pourraient s'avérer très utiles pour ceux d'un autre, mais la plupart des entreprises laissent ces données disparaître dans les boîtes de réception des employés, où leur potentiel de levier est perdu dans le vide.
Une meilleure solution est basé sur l'apprentissage automatique les systèmes de compréhension du langage naturel (NLU), qui automatisent trouver, identifier et étiqueter processus, résultant en des «entités marquées» ou des «entités extraites». NLU est une approche plus large du traitement traditionnel du langage naturel (NLP), qui tente de comprendre les variations de texte comme représentant la même information sémantique (signification). Avec les entités extraites jusqu'au niveau de la phrase, on peut alors effectuer toutes sortes de analyse de texte, comme la cartographie thermique et les regroupements qui mènent à des informations. L'analyse des sentiments est une autre analyse textuelle très populaire utilisée pour comprendre de grands corpus (ensembles agrégés) de texte.
Chez CityFALCON, nous venons de lancer un système d'extraction d'entités NLU et une analyse des sentiments spécialement conçus pour le contenu commercial, financier et politique dans plusieurs langues pour les entités identifiées et pour des documents entiers, des actualités, des journaux de discussion et des chaînes de courrier électronique.
Le besoin
Il existe plusieurs raisons d'identifier et d'étiqueter des produits, des entreprises, des personnes et d'autres sujets dans le texte. L'une des raisons est que les gouvernements ont des exigences de conservation des documents, et certaines entreprises ont de très grands ensembles de documents conservés qui ne sont pas organisés et inutilisés pour une analyse plus approfondie du Big Data.
D'autres entreprises conservent simplement tous leurs messages et documents internes pour référence future ou pour une analyse Big Data plus tard. Si le texte est généré en interne, il y a peut-être quelques balises dessus, mais elles ne décrivent pas très profondément le contenu à l'intérieur. Si le texte est créé en externe, comme le contenu d'actualités, les balises peuvent être insuffisantes, inexactes ou inexistantes.
Quel que soit le cas, seule une compréhension limitée d'un texte peut être dérivée des balises de niveau supérieur, des titres de sections et des résumés de section. Les métadonnées existent à travers toutes les couches d'un texte, et NLU peut aider à mieux comprendre des documents uniques ainsi que tout un corpus. Étant donné que NLU fonctionne aussi granulairement que le niveau de la phrase, les documents peuvent être analysés de manière algorithmique par phrase et la sortie traitée pour un aperçu puissant.
L'une des promesses du Big Data est de traiter des quantités d'informations que des humains ou des équipes ne pourraient tout simplement pas. Parce que notre esprit humain ne peut contenir qu'une quantité limitée d'informations à la fois et que la communication entre les humains est limitée par la rapidité avec laquelle nous pouvons transférer des pensées à travers le langage, comprendre trois millions de pages d'articles, de documentation et d'e-mails n'est pas un exploit pour un humain. ou même une équipe. Il s'agit pour les machines de se distiller en morceaux beaucoup plus faciles à gérer.
La NLU et les analyses associées aident les entreprises à organiser leur contenu, à le rendre plus rapide à rechercher avec des mots-clés et à offrir des informations que l'esprit humain ne peut tout simplement pas synthétiser (bien que nous puissions comprendre le résultat, bien sûr).
Ainsi, partout où il est nécessaire d'organiser, de catégoriser et de comprendre de grands volumes d'informations textuelles à haute résolution, le système NLU de CityFALCON peut fournir des informations et une analyse inter-services en toute simplicité.
Comment ça fonctionne
À un niveau élevé, notre API nouvellement lancée décompose tout ensemble de texte en ses phrases constitutives puis identifie tous les entités dans chaque phrase. Par exemple, prenons un titre récent:
Les contrats à terme boursiers chutent après les bénéfices, la menace de Trump pour les tarifs chinois sur la pandémie
Lesquels nos systèmes se diviseront ainsi:
Stocks = instrument financier
Futures = instrument financier
Gains = un événement
Trump = la personne
Chine = emplacement
Tarifs = sujet_financier
Pandémie = sujet_financier
Et si vous voulez voir la réponse JSON dans son intégralité, nous l'avons publiée ici pour vous.
{"Text": "Les contrats à terme boursiers baissent après les bénéfices, la menace de Trump pour les tarifs chinois sur la pandémie",
"Lang": "en",
"Mots clés": [
{
«Start»: 0,
«Fin»: 5,
"Valeur": "Stock",
"Type": "instrument_financier",
"Apparié": vrai,
«Entités»: [
{
«Name»: «Stocks»,
"Type": "topic_classes",
"Métadonnées": {}
}
]
},
{
«Démarrer»: 6,
«Fin»: 13,
«Value»: «futures»,
"Type": "instrument_financier",
"Apparié": vrai,
«Entités»: [
{
"Name": "Futures",
"Type": "Financial_topics",
"Métadonnées": {}
}
]
},
{
«Début»: 25,
«Fin»: 33,
"Valeur": "revenus",
"Type": "événement",
"Apparié": vrai,
«Entités»: [
{
"Nom": "Revenus",
"Type": "major_business_and_related_activities",
"Métadonnées": {}
}
]
},
{
«Début»: 36,
«Fin»: 43,
«Valeur»: «Trump»,
"Type": "personne",
"Apparié": vrai,
«Entités»: [
{
«Name»: «Trump Family»,
"Type": "personnes",
"Métadonnées": {}
}
]
},
{
«Début»: 55,
«Fin»: 60,
"Valeur": "Chine",
"Type": "emplacement",
"Apparié": vrai,
«Entités»: [
{
"Nom": "Chine",
"Type": "geo_regions",
"Métadonnées": {
"des pays": [
"Chine"
],
«Sous-continents»: [
"Asie de l'Est"
],
«Continents»: [
"Asie"
]
}
}
]
},
{
«Début»: 61,
«Fin»: 68,
"Valeur": "tarifs",
"Type": "thème_financier",
"Apparié": vrai,
«Entités»: [
{
"Name": "Tarifs",
"Type": "Financial_topics",
"Métadonnées": {}
}
]
},
{
«Début»: 74,
«Fin»: 82,
«Valeur»: «pandémie»,
"Type": "thème_financier",
"Apparié": vrai,
«Entités»: [
{
«Nom»: «Pandémie»,
"Type": "other_topics",
"Métadonnées": {}
}
]
}
]
}
Plus loin, prenez l'entité Chine. Parce qu'il a été «mis en correspondance» dans notre base de données, il est également associé à une hiérarchie. Cela signifie le terme Chine peut désormais être renvoyé lorsque quelqu'un effectue une recherche en Asie de l'Est ou en Asie, ce qui permet une bien meilleure indexation du contenu interne.
En plus des hiérarchies, les entités correspondantes peuvent regrouper plusieurs noms. Un tel exemple est le terme «Coronavirus», qui correspondra dans nos systèmes à «COVID-19», «covid19» et «covid», parmi de nombreux autres mots et phrases courtes connexes. Cela permet à un employé de rechercher un seul terme et de recevoir tous les éléments connexes, même si une simple recherche de texte échouait, car la recherche de texte simple COVID-19 [FEMININE ne renverra pas les mentions de Coronavirus.
Regardons un autre exemple. Celui-ci pourrait être un message de chat entre employés:
- Vous pensez que les États-Unis vont lancer une enquête contre Facebook?
Encore une fois, voici le JSON renvoyé par nos systèmes.
{
«Text»: «vous pensez que les États-Unis vont lancer une enquête contre Facebook»,
"Lang": "en",
"Mots clés": [
{
«Début»: 14,
«Fin»: 16,
"Value": "US",
"Type": "emplacement",
"Apparié": vrai,
«Entités»: [
{
"Name": "États-Unis d'Amérique",
"Type": "geo_regions",
"Métadonnées": {
"des pays": [
"Les États-Unis d'Amérique"
],
«Sous-continents»: [
«Amérique du Nord»
],
«Continents»: [
"Amérique du Nord"
]
}
}
]
},
{
«Début»: 51,
«Fin»: 59,
"Valeur": "Facebook",
"Type": "société",
"Apparié": vrai,
«Entités»: [
{
«Nom»: «Facebook Inc»,
"Type": "actions",
"Métadonnées": {
"Legal_ids": [
"0201665019_irs-us",
«0001326801_sec-us»
],
"Tickers": [
"FB_US"
],
"Catégories": [
"Des médias sociaux"
],
«Sous-industries»: [
«Services Internet et infrastructure»
],
"les industries": [
"Services informatiques"
],
«Secteurs»: [
"La technologie",
«Communications»
]
}
}
]
},
{
«Début»: 22,
«Fin»: 42,
"Value": "lancer une enquête",
"Type": "événement",
"Correspondant": faux
}
]
}
Ici, le «US» est une entité appariée et contient également une hiérarchie. Le sujet spécifique les États-Unis d'Amérique sera identifiable avec «États-Unis», «États-Unis» et «Amérique», et il peut également être trouvé lorsque quelqu'un effectue une recherche en Amérique du Nord. Ainsi, lorsqu'un employé se souvient vaguement du fil de conversation sur «Amérique», il ne sera pas frustré par le décalage entre son terme de recherche, «Amérique», et le terme réel utilisé, «US». Dans une recherche de texte standard, la tentative de recherche de la conversation peut échouer.
Les entreprises font également partie d'une hiérarchie dans l'économie, et la recherche de services informatiques garantira que «Facebook» est également inclus dans les résultats. Non seulement cela, mais parce que Facebook est une entreprise publique, ses numéros d'identité légale, y compris son identifiant SEC et son (ses) ticker (s) par pays, sont retournés. Cela pourrait être lié aux dépôts de l'entreprise ou alimenté par programme dans un autre algorithme qui récupère SEC dépôts de CityFALCON ou servir à croiser les affaires judiciaires dans le système judiciaire américain.
Enfin, il peut également être utile de sélectionner des actions dans n'importe quelle conversation ou rapport de recherche. Le phrasé lancer une enquête a été ramassé par notre apprentissage automatique systèmes en tant que un événement. Ces données aident à déterminer le thème d'un texte, et un bon cas d'utilisation serait de marquer les e-mails avec leurs événements. Dans cet exemple, le un événement était ne pas appariés, mais des dizaines de milliers d'événements sur CityFALCON sont mis en correspondance de la même manière que les emplacements et les entreprises peuvent être mis en correspondance avec les données associées.
Puisque les machines ne se soucient pas si vous avez 1 ou 100 000 phrases, ce même processus peut être répété indéfiniment pour n'importe quel corpus de taille. Tout cela sera traité en quelques secondes avec notre algorithme le traitant sur un GPU rapide.
La portée du système CityFALCON
Nous identifions 20 groupes d'entités personnalisées et plus de 300 000 sujets relatifs aux «entités nommées» spécifiques à la finance, ajoutant une couche approfondie d'analyse possible pour les banques, les gouvernements, les universités et les autres utilisateurs qui ont besoin d'une analyse de contenu basée sur des conditions économiques et financières. au-delà des produits de concurrents comme IBM ou Microsoft, dont les systèmes sont conçus pour un contenu général.
Par exemple, un seul sujet couvre l'idée des «États-Unis d'Amérique», où les noms associés, comme «États-Unis», «Amérique» et «États-Unis» sont tous considérés comme faisant partie de ce sujet, tout comme les métadonnées (pour emplacements c'est la hiérarchie géographique). Tous les sujets sont accompagnés des informations associées et, le cas échéant, des hiérarchies et des noms associés. Ils vont des emplacements aux personnes en passant par les entreprises et les produits, et vous pouvez même les parcourir dans notre Annuaire si vous voulez tous les voir. Grâce à l'API, vous pourrez indexer votre propre contenu de la même manière, et cette capacité est un énorme réservoir de pouvoir d'organisation.
Avec tous ces sujets et groupes d'entités, NLU en tant que outil cognitif transforme la recherche d'un instrument qui fortifie une idée déjà présente dans l'esprit en un instrument qui construit des idées basées sur des concepts. Au lieu de rechercher un document ou une chaîne d'e-mails spécifique biotechnologies, les travailleurs peuvent rechercher des balises de secteur. Peut-être qu'un autre secteur est souvent mentionné avec la biotechnologie, qui sert de voie de perspective potentielle. À l'inverse, on peut souhaiter trouver tous les mouvements de prix dans une chaîne de courrier électronique ou un ensemble de 15000 actualités, indépendamment de la direction et du vocabulaire spécifique utilisés (surtension, pointe, saut, montée en flèche, tirer, etc.).
Au moment de la publication de ce billet de blog, les systèmes CityFALCON sont prêts à accepter le contenu anglais et russe. L'ukrainien et l'espagnol seront acceptés cet été, et d'autres langues seront ajoutées au fur et à mesure que nos systèmes seront développés grâce à notre Projet de R&D en cours à Malte, qui comprend le mandarin, le japonais, le coréen, l'allemand, le français, le portugais et d'autres. Finalement, nous couvrirons plus de 90 langues.
NLU pour le contenu interne
Le cœur de CityFALCON est NLU: nous collectons, regroupons et traitons les actualités et le contenu financiers - nous en comprenons le langage - et les livrons aux utilisateurs en temps réel. Nous ajoutons des analyses en plus, comme un score de pertinence, un sentiment et d'autres idées en cours de développement.
Cet énorme moteur de compréhension du langage principalement financier et économique fonctionne bien pour toutes les données que nous nous approvisionnons. Cela fonctionnera aussi bien sur les données texte du client, que ce soit recherche exclusive, rapports économiques, relevés de notes d'appels de résultats ou simples mémos et e-mails.
Notre moteur NLU propriétaire est prêt à être utilisé par les clients pour indexer et organiser leur propre contenu. Le moteur NLU a été affiné par notre équipe d'analystes financiers et NLU au cours des trois dernières années sur des articles de presse, des tweets et des dépôts réglementaires. Maintenant, ce pouvoir peut être appliqué au contenu financier interne que vous souhaitez indexer.
Un portail des employés potentiels peut afficher les composants suivants.
Contenu externe
Nous fournissons ce contenu à partir de nos plus de 5000 sources et de Twitter. Nous vous enverrons des nouvelles, des tweets, des états financiers et des dépôts réglementaires, un score de pertinence CityFALCON, des données NLU de contenu externe et une analyse des sentiments.
Contenu interne
Cela provient de tout texte fourni par le client, comme la correspondance interne, les publications et le courrier électronique informel entre les départements.
Contenu inter-organisationnel
Certaines des balises renvoyées contiennent non seulement des noms, mais également des informations importantes telles que la position dans les hiérarchies économiques, telles que les secteurs et sous-secteurs, ainsi que des informations juridiques telles que les numéros d'identification et les symboles de l'entreprise. Ceux-ci peuvent renforcer davantage votre recherche ou automatiser certains processus, comme afficher la dernière cotation boursière d'une bourse pour vos traders.
Chat en temps réel
Les conversations des employés sont balisées au fur et à mesure qu'elles se déroulent, ce qui fournit des informations interrogeables, telles que la fréquence à laquelle une équipe mentionne un secteur ou une personne clé au cours d'une semaine de travail. Cela permet aux décideurs de découvrir des informations autrement obscurcies mais utiles. Si tout le monde parle de X, alors X pourrait bien être le prochain grand mouvement sur les marchés.
Cela permet également aux employés de parcourir les fils de discussion passés et de rechercher par entité ou groupe d'entités au lieu d'un mot-clé spécifique, élargissant ainsi le potentiel de connexion. Par exemple, quelqu'un pourrait vouloir connaître toutes les instances d'un collègue spécifique mentionnant «instrument_financier» ou «entreprise», quelles que soient les spécificités.
Le chat en temps réel pourrait même générer un fil d'actualité en temps réel qui s'adapte au sujet actuel de la conversation.
Visualisations
Ce composant permet d'appréhender en un coup d'œil la structure et les thèmes d'un ensemble de textes, qu'il s'agisse de fils de discussion avec les clients, d'actualités de la semaine ou de comptes rendus de réunion. La mise en page et la conception devront être implémentées du côté de l'entreprise, mais CityFALCON peut fournir des données NLU structurées comme base de ce composant.
Un seul exemple d'analyse ad hoc de la force d'une tendance pourrait être visualisé dans la force des mots employés. Si tous les titres disent «dérive vers le bas», «lutte» et «flotte plus bas», vous savez que la situation n'est pas aussi mauvaise que s'ils disaient tous «plonger», «imploser» et «décimer». En utilisant CityFALCON NLU, ce type d'analyse à la volée devient aussi simple que de regarder toutes les instances d'un price_movement tag dans un ensemble de textes.
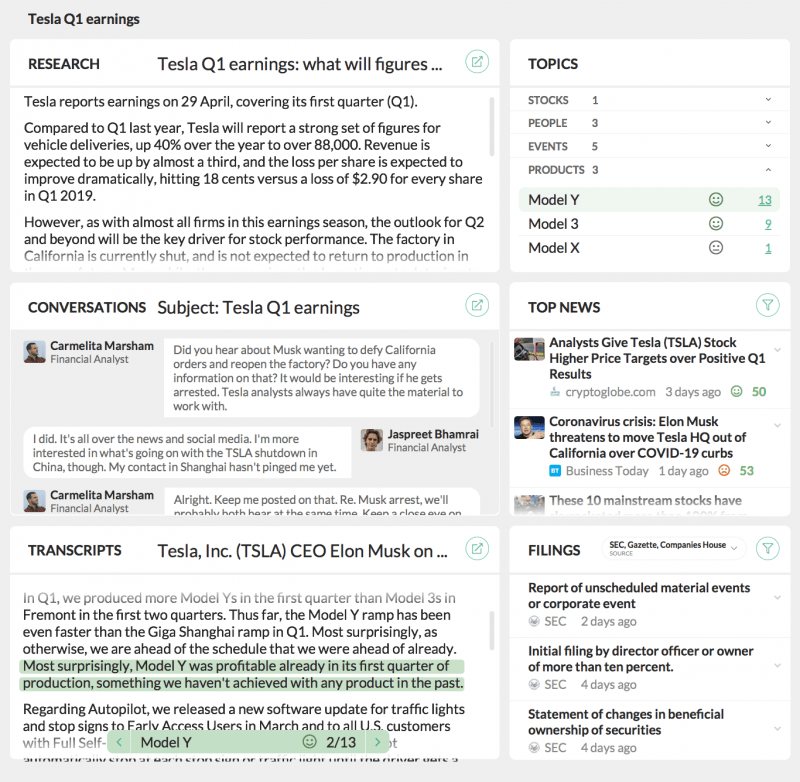
Un tableau de bord des employés potentiels de contenu interne et externe
Pourquoi payer le service?
Certains peuvent affirmer que la construction de ces systèmes eux-mêmes est facile ou nécessite peu de ressources. Certains peuvent tenter d'externaliser l'étiquetage et l'organisation à une main-d'œuvre étrangère bon marché, tandis que d'autres peuvent essayer d'embaucher quelques développeurs pour le faire en interne. Aucune de ces solutions ne résout le problème de manière adéquate, et elles passent à côté d'une valeur ajoutée très importante.
Premièrement, le volume même du contenu peut ne pas pouvoir être traité par des humains, de sorte que le traitement manuel n'est pas applicable. De plus, il n'est pas possible d'appliquer l'extraction manuelle NLU aux chats et autres sources en constante évolution en temps réel. C'est possible avec l'apprentissage automatique et les systèmes automatisés.
Deuxièmement, ces systèmes prennent beaucoup de temps à construire et à mettre en œuvre. Non seulement les algorithmes nécessitent une formation, mais ils doivent être testés et ajustés. La mise en place du système entier peut prendre des années, alors qu'il est possible d'obtenir une licence pour la technologie maintenant.
Troisièmement, la «compréhension» et la structure sous-jacentes de tout l'appareil doivent s'adapter à mesure que de nouvelles idées et concepts arrivent dans le monde. Dans les affaires et la politique, il y a constamment de nouvelles personnes, entreprises, lois et événements qui doivent être suivis. Vous auriez besoin d'une équipe entière pour suivre tout cela et mettre à jour les algorithmes en conséquence - heureusement, CityFALCON le fait déjà pour vous avec notre équipe d'analystes financiers multilingues.
Ces systèmes peuvent-ils être construits et entretenus en interne? Oui. Cependant, leur construction et leur entretien ultérieur deviennent rapidement coûteux et prennent du temps, en particulier dans des domaines en évolution rapide tels que la finance, les affaires et la politique. CityFALCON peut gérer les détails techniques. Vous vous concentrez sur le client et les affaires.
En fin de compte, la valeur réside dans les données. Avec le produit CityFALCON, la valeur latente peut être extraite de sources textuelles financières et économiques et canalisée vers des activités génératrices de revenus comme le trading et la gestion de portefeuille. Nous pouvons vous aider à enrichir vos métadonnées jusqu'aux mots des phrases, à connecter des entités individuelles aux informations associées et à créer des connexions de type Web entre toutes les parties de votre entreprise.
Sécurité et confidentialité
Étant donné que la sécurité et la confidentialité sont primordiales en ce qui concerne la documentation interne ou la correspondance privée entre clients et employés, notre système garantit que vos données sont entre de bonnes mains.
En évitant les détails techniques, tout le texte que vous envoyez sera envoyé via un tunnel crypté HTTPS normal, de sorte que personne ne peut lire les données de demande que vous envoyez. Ensuite, sur nos serveurs, vos données résident temporairement dans la RAM pendant leur traitement. Une fois traitées, toutes les traces de vos données disparaissent de notre système. Cela signifie que le texte n'est jamais écrit sur le disque ou stocké dans notre base de données.
Si quelqu'un pirate nos systèmes ou si un employé malveillant tente de vendre des informations client, il n'y a pas de données à voler. Le contenu passé a été irrémédiablement effacé. Le seul inconvénient est que votre demande n'est pas mise en cache, donc si vous devez ré-extraire du même ensemble de texte - peut-être qu'elle a été accidentellement supprimée sur un ordinateur interne - vous devrez la retransmettre. Cependant, la nécessité de retravailler un document est assez rare.
À l'inverse, pour ceux qui veulent vraiment garder les choses locales, nous pouvons proposer un déploiement de système local avec mises à jour régulières, ainsi l'ensemble du processus NLU peut avoir lieu sur le site client, les données ne quittant jamais leurs propres systèmes.
Intégration pratique
Grâce à notre API, toute entreprise peut désormais indexer son contenu interne à partir de la documentation passée ou en temps réel. C'est aussi simple que d'interroger le point de terminaison de l'API pour l'extraction d'entités (balisage NLU) et de vous autoriser avec la clé unique de votre entreprise. Bien sûr, vous devrez créer votre propre tableau de bord et interface pour vos propres utilisateurs, mais nous nous occuperons de tous lesng en NLU - c'est le service que nous fournissons, après tout.
Nous contacter pour mettre en place une démonstration et discuter des cas d'utilisation potentiels, des limites d'appels et de toute autre question que vous pourriez avoir.
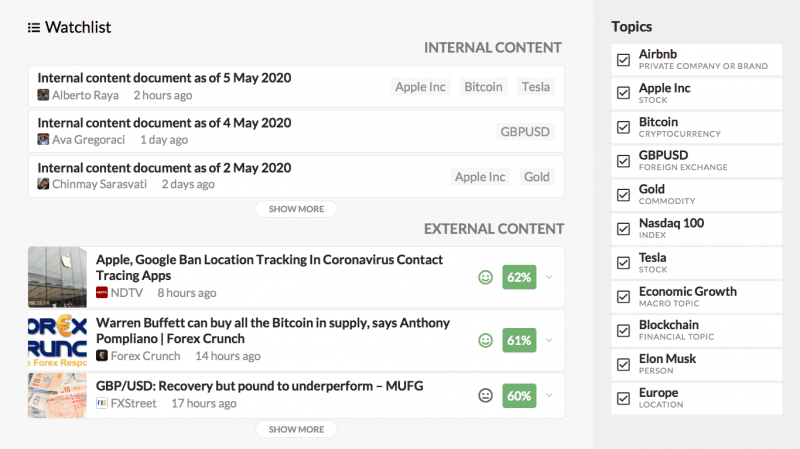
Une vue interne plus simple avec une liste de surveillance associée
Laisser un commentaire