


Immagina lo scenario: 75.000 documenti e tonnellate di notizie, ricerche e messaggi di chat da vagliare, etichettare e classificare senza uno schema distinguibile nella loro sequenza. Vuoi ordinarli per azienda e per posizione, ma senza i tag di primo livello, per pagina e per frase l'attività sembra quasi impossibile. Il 14.198° documento è un rapporto macroeconomico su Nord America, Cina, Tokyo o l'interazione di tutti e tre? Fa il 47.938° documento discutere di dividendi, guadagni o lancio di un nuovo prodotto? L'email del cliente di 6 mesi fa fa riferimento a Google, Alphabet o GOOG? Ancora peggio, alcune serie di testi possono essere lunghe centinaia di pagine e contenere molti argomenti diversi e parti di dati importanti. Titoli, sommari e tag di primo livello possono solo dirti così tanto.
Voi Potevo assumere persone per leggere, comprendere e organizzare manualmente ogni singolo documento, e-mail, notizia e messaggio di chat. Sfortunatamente, ciò consuma molto tempo e risorse finanziarie, e con registri di chat, e-mail, articoli di notizie e rapporti che crescono ogni giorno, potrebbe essere impossibile indicizzare effettivamente tutto il contenuto usando gli occhi e le menti umane. I messaggi tra i dipendenti di un reparto potrebbero rivelarsi molto utili per quelli di un altro, ma la maggior parte delle aziende lascia che questi dati scompaiano nelle caselle di posta dei dipendenti, dove il loro potenziale di leva si perde nel vuoto.
Una soluzione migliore è basato sull'apprendimento automatico sistemi di comprensione del linguaggio naturale (NLU), che automatizzano il trovare, identificare e taggare processo, risultando in "entità contrassegnate" o "entità estratte". NLU è un approccio più ampio all'elaborazione del linguaggio naturale tradizionale (NLP), che tenta di comprendere le variazioni nel testo come rappresentanti della stessa informazione semantica (significato). Con le entità estratte fino al livello della frase, si possono quindi eseguire tutti i tipi di analisi del testo, come la mappatura termica e i raggruppamenti che portano a approfondimenti. L'analisi del sentimento è un'altra analitica testuale molto popolare utilizzata per comprendere grandi corpora (insiemi aggregati) di testo.
A CityFALCON, abbiamo appena lanciato un sistema di estrazione di entità NLU e un'analisi del sentiment sintonizzata specificamente per contenuti aziendali, finanziari e politici in più lingue per entità identificate e per interi documenti, notizie, registri di chat e catene di e-mail.
L'esigenza
Esistono diversi motivi per identificare e contrassegnare prodotti, aziende, persone e altri argomenti nel testo. Uno dei motivi è che i governi hanno requisiti di conservazione dei documenti e alcune aziende hanno insiemi molto ampi di documenti conservati che non sono organizzati e non vengono utilizzati per ulteriori analisi dei Big Data.
Altre aziende conservano semplicemente tutti i loro messaggi e documenti interni per riferimento futuro o per l'analisi dei Big Data in seguito. Se il testo è generato internamente, forse hanno alcuni tag su di essi, ma non descrivono molto profondamente il contenuto all'interno. Se il testo è creato esternamente, come il contenuto delle notizie, i tag potrebbero essere insufficienti, imprecisi o inesistenti.
In ogni caso, solo una comprensione limitata di un testo può essere derivata da tag di primo livello, titoli di sezioni e riepiloghi di sezioni. I metadati esistono attraverso tutti i livelli di un testo e la NLU può aiutare a comprendere meglio singoli documenti così come un intero corpus. Poiché l'NLU funziona in modo granulare come il livello della frase, i documenti possono essere analizzati algoritmicamente per frase e l'output elaborato per una visione approfondita.
Una delle promesse dei Big Data è quella di elaborare quantità di informazioni che i singoli esseri umani o gruppi di loro semplicemente non potrebbero. Poiché le nostre menti umane possono contenere solo così tante informazioni contemporaneamente e la comunicazione tra esseri umani è limitata dalla velocità con cui possiamo trasferire i pensieri attraverso il linguaggio, comprendere tre milioni di pagine di notizie, documentazione ed e-mail non è un'impresa per un essere umano o anche una squadra. Spetta alle macchine distillare in bit molto più gestibili.
L'NLU e l'analisi associata aiutano le aziende a organizzare i loro contenuti, a renderli più rapidamente ricercabili con parole chiave e possono offrire approfondimenti che le menti umane semplicemente non sono in grado di sintetizzare (sebbene possiamo capire l'output, ovviamente).
Pertanto, ovunque vi sia la necessità di organizzare, classificare e comprendere grandi volumi di informazioni testuali ad alta risoluzione, il sistema NLU di CityFALCON può fornire facilmente approfondimenti e analisi interdipartimentali.
Come funziona
Ad alto livello, la nostra API appena lanciata suddivide qualsiasi insieme di testo nelle sue frasi costitutive, quindi identifica tutti i file entità in ogni frase. Ad esempio, prendiamo un titolo recente:
I futures sulle azioni crollano dopo gli utili, la minaccia di Trump per i dazi cinesi a causa della pandemia
Quali i nostri sistemi si divideranno in questo modo:
Azioni = strumenti finanziari
Futuri = strumenti finanziari
Guadagno = evento
Trump = persona
Cina = Posizione
Tariffe = argomento_finanziario
Pandemia = argomento_finanziario
E se vuoi vedere la risposta JSON per intero, l'abbiamo pubblicata qui per te.
{“testo”: “I futures sulle azioni scendono dopo gli utili, la minaccia di Trump per le tariffe cinesi a causa della pandemia”,
“lang”: “it”,
“tag”: [
{
“inizio”: 0,
“fine”: 5,
“valore”: “Stock”,
“tipo”: “strumento_finanziario”,
“corrispondente”: vero,
"entità": [
{
“nome”: “azioni”,
“tipo”: “classi_argomento”,
"metadati": {}
}
]
},
{
“inizio”: 6,
“fine”: 13,
“valore”: “futuri”,
“tipo”: “strumento_finanziario”,
“corrispondente”: vero,
"entità": [
{
“nome”: “Future”,
“tipo”: “argomenti_finanziari”,
"metadati": {}
}
]
},
{
“inizio”: 25,
“fine”: 33,
“valore”: “guadagno”,
“tipo”: “evento”,
“corrispondente”: vero,
"entità": [
{
“nome”: “Guadagni”,
“tipo”: “attività_importanti_e_attività_correlate”,
"metadati": {}
}
]
},
{
“inizio”: 36,
“fine”: 43,
"valore": "Trump",
“tipo”: “persona”,
“corrispondente”: vero,
"entità": [
{
“nome”: “Famiglia Trump”,
“tipo”: “persone”,
"metadati": {}
}
]
},
{
“inizio”: 55,
“fine”: 60,
“valore”: “Cina”,
“tipo”: “posizione”,
“corrispondente”: vero,
"entità": [
{
“nome”: “Cina”,
“tipo”: “geo_regioni”,
"metadati": {
"Paesi": [
"Cina"
],
“subcontinenti”: [
"Asia orientale"
],
“continenti”: [
"Asia"
]
}
}
]
},
{
“inizio”: 61,
“fine”: 68,
“valore”: “tariffe”,
"tipo": "argomento_finanziario",
“corrispondente”: vero,
"entità": [
{
“nome”: “Tariffe”,
“tipo”: “argomenti_finanziari”,
"metadati": {}
}
]
},
{
“inizio”: 74,
“fine”: 82,
“valore”: “pandemia”,
"tipo": "argomento_finanziario",
“corrispondente”: vero,
"entità": [
{
“nome”: “Pandemia”,
“tipo”: “altri_argomenti”,
"metadati": {}
}
]
}
]
}
Inoltre, prendi l'entità Cina. Poiché è stato "abbinato" nel nostro database, ha anche una gerarchia ad esso associata. Questo significa il termine Cina ora può essere restituito quando qualcuno cerca anche in Asia orientale o in Asia, consentendo un'indicizzazione molto migliore dei contenuti interni.
Oltre alle gerarchie, le entità corrispondenti possono raggruppare più nomi insieme. Uno di questi esempi è il termine "Coronavirus", che verrà abbinato nei nostri sistemi a "COVID-19", "covid19" e "covid", tra molte altre parole correlate e brevi frasi. Ciò consente a un dipendente di cercare un singolo termine e ricevere tutti gli elementi correlati, anche se una semplice ricerca di testo fallirebbe, perché la ricerca di testo semplice COVID-19 non restituirà menzioni di Coronavirus.
Diamo un'occhiata a un altro esempio. Questo potrebbe essere un messaggio di chat tra dipendenti:
– Pensi che gli Stati Uniti avvieranno un'indagine contro Facebook?
Di nuovo, ecco il JSON restituito dai nostri sistemi.
{
“testo”: “pensi che gli Stati Uniti avvieranno un'indagine contro Facebook”,
“lang”: “it”,
“tag”: [
{
“inizio”: 14,
“fine”: 16,
"valore": "USA",
“tipo”: “posizione”,
“corrispondente”: vero,
"entità": [
{
“nome”: “Stati Uniti d'America”,
“tipo”: “geo_regioni”,
"metadati": {
"Paesi": [
"Stati Uniti d'America"
],
“subcontinenti”: [
“Nordamerica”
],
“continenti”: [
"Nord America"
]
}
}
]
},
{
“inizio”: 51,
“fine”: 59,
“valore”: “Facebook”,
“tipo”: “azienda”,
“corrispondente”: vero,
"entità": [
{
“nome”: “Facebook Inc”,
“tipo”: “azioni”,
"metadati": {
"ID_legali": [
“0201665019_irs-us”,
“0001326801_sec-us”
],
"ticker": [
"FB_US"
],
“categorie”: [
"Social Media"
],
“sottosettori”: [
"Servizi e infrastrutture Internet"
],
“industrie”: [
"Servizi IT"
],
“settori”: [
"Tecnologia",
“Comunicazioni”
]
}
}
]
},
{
“inizio”: 22,
“fine”: 42,
“valore”: “avvio indagine”,
“tipo”: “evento”,
“corrispondente”: falso
}
]
}
Qui "US" è un'entità corrispondente e contiene anche una gerarchia. L'argomento specifico Stati Uniti d'America sarà identificabile con "gli Stati Uniti", "Stati Uniti" e "America" e può essere trovato anche quando qualcuno cerca nel Nord America. Pertanto, quando un dipendente ricorda vagamente il thread di conversazione su "America", non sarà frustrato dalla mancata corrispondenza tra il termine di ricerca, "America", e il termine effettivamente utilizzato, "USA". In una normale ricerca di testo, il tentativo di trovare la conversazione potrebbe fallire.
Anche le aziende fanno parte di una gerarchia nell'economia e la ricerca di servizi IT assicurerà che anche "Facebook" sia incluso nei risultati. Non solo, ma poiché Facebook è una società pubblica, vengono restituiti i suoi numeri di identità legale, incluso l'identificatore SEC e i ticker per paese. Questo potrebbe essere collegato ai documenti dell'azienda o inserito a livello di codice in un altro algoritmo che recupera SEC depositi da CityFALCON o essere utilizzato per riferimenti incrociati a casi giudiziari nel sistema giudiziario statunitense.
Infine, potrebbe anche essere utile individuare azioni da qualsiasi conversazione o rapporto di ricerca. Il fraseggio avviare un'indagine è stato prelevato dal ns apprendimento automatico sistemi come un evento. Questi dati aiutano a determinare il tema di un testo e un buon caso d'uso sarebbe contrassegnare le e-mail con i loro eventi. In questo esempio, il evento era non abbinati, ma ci sono decine di migliaia di eventi su CityFALCON che vengono abbinati nello stesso modo in cui le località e le aziende possono essere abbinate ai dati associati.
Poiché alle macchine non importa se hai 1 o 100.000 frasi, questo stesso processo può essere ripetuto all'infinito per corpus di qualsiasi dimensione. Tutto questo verrà elaborato in pochi secondi con il nostro algoritmo che lo elabora su una GPU veloce.
L'ambito del sistema CityFALCON
Identifichiamo 20 gruppi di entità personalizzate e più di 300.000 argomenti di "entità denominate" specifici per la finanza, aggiungendo uno strato profondo di possibili analisi per banche, governi, università e altri utenti che necessitano di analisi dei contenuti basata su termini economici e finanziari, andando oltre i prodotti di concorrenti come IBM o Microsoft, i cui sistemi sono progettati per contenuti generali.
Ad esempio, un singolo argomento copre l'idea di "Stati Uniti d'America", dove i nomi associati, come "US", "America" e "USA" sono tutti considerati parte di quell'unico argomento, così come i metadati (per posizioni questa è la gerarchia geografica). Tutti gli argomenti vengono forniti con informazioni associate e, se disponibili, gerarchie e nomi associati. Si va da luoghi a persone ad aziende e prodotti, e puoi persino sfogliarli nel nostro Direttorio se vuoi vederli tutti Attraverso l'API sarai in grado di indicizzare i tuoi contenuti allo stesso modo, e questa capacità è un enorme serbatoio di potere organizzativo.
Con tutti questi argomenti e gruppi di entità, NLU as a strumento conoscitivo trasforma la ricerca da strumento che fortifica un'idea già presente nella mente a strumento che costruisce idee basate su concetti. Invece di cercare un documento specifico o una catena di e-mail Biotecnologia, i lavoratori possono cercare tag di settore. Forse un altro settore è comunemente menzionato insieme alle biotecnologie, che funge da via di potenziale approfondimento. Al contrario, si potrebbe desiderare di trovare tutti i movimenti di prezzo in una catena di e-mail o in un insieme di 15.000 notizie, indipendentemente dalla direzione e dal vocabolario specifico utilizzato (slancio, picco, salto, razzo, spara in alto, eccetera.).
Al momento della pubblicazione di questo post sul blog, i sistemi CityFALCON sono pronti ad accettare contenuti in inglese e russo. L'ucraino e lo spagnolo saranno accettati quest'estate e altre lingue verranno aggiunte man mano che i nostri sistemi verranno sviluppati attraverso il nostro Progetto di ricerca e sviluppo in corso a Malta, che include mandarino, giapponese, coreano, tedesco, francese, portoghese e altri. Alla fine, copriremo più di 90 lingue.
NLU per contenuto interno
Il nucleo di CityFALCON è NLU: raccogliamo, aggreghiamo ed elaboriamo notizie e contenuti finanziari - ne comprendiamo il linguaggio - e li forniamo agli utenti in tempo reale. Aggiungiamo alcune analisi in cima, come un punteggio di pertinenza, un sentimento e alcune altre idee in fase di sviluppo.
Questo enorme motore di comprensione principalmente del linguaggio finanziario ed economico funziona bene per tutti i dati che ci procuriamo noi stessi. Funzionerà altrettanto bene sui dati di testo del cliente, sia esso ricerca proprietaria, rapporti economici, trascrizioni chiamate guadagni o semplici interni promemoria ed e-mail.
Il nostro motore NLU proprietario è pronto per essere utilizzato dai clienti per indicizzare e organizzare i propri contenuti. Il motore NLU è stato perfezionato dal nostro team di analisti finanziari e NLU negli ultimi tre anni su articoli di notizie, tweet e documenti normativi. Ora quel potere può essere applicato ai contenuti finanziari interni che desideri indicizzare.
Un potenziale portale per i dipendenti può visualizzare i seguenti componenti.
Contenuto esterno
Forniamo questo contenuto dalle nostre oltre 5000 fonti e da Twitter. Ti invieremo notizie, tweet, rendiconti finanziari e documenti normativi, un punteggio di pertinenza CityFALCON, dati NLU sui contenuti esterni e analisi del sentiment.
Contenuto interno
Questo deriva da qualsiasi testo fornito dal cliente, come la corrispondenza interna, le pubblicazioni e le e-mail informali tra i reparti.
Contenuto interorganizzativo
Alcuni dei tag restituiti contengono non solo nomi, ma anche informazioni importanti come la posizione nelle gerarchie economiche, come settori e sottoindustrie, oltre a informazioni legali come numeri di identificazione dell'azienda e ticker. Questi possono potenziare ulteriormente la tua ricerca o automatizzare alcuni processi, come richiamare l'ultima quotazione di borsa da uno scambio per i tuoi trader.
Chatta in tempo reale
Le conversazioni dei dipendenti vengono contrassegnate man mano che si verificano, fornendo approfondimenti ricercabili come la frequenza con cui un team menziona un settore o una persona chiave durante una settimana lavorativa. Ciò consente ai decisori di scoprire informazioni altrimenti nascoste ma utili. Se tutti parlano di X, allora X potrebbe essere solo la prossima grande mossa nei mercati.
Ciò consente inoltre ai dipendenti di esaminare i thread di chat passati e cercare per entità o gruppo di entità invece che per parola chiave specifica, ampliando il potenziale per stabilire connessioni. Ad esempio, qualcuno potrebbe voler conoscere tutte le istanze di un collega specifico che menziona "strumento_finanziario" o "azienda", indipendentemente dalle specifiche.
La chat in tempo reale potrebbe persino guidare un feed di notizie in tempo reale che si adatta all'argomento corrente della conversazione.
Visualizzazioni
Questo componente permette di comprendere a colpo d'occhio la struttura ei temi di un insieme di testi, siano essi thread di posta elettronica con i clienti, notizie della settimana o verbali di riunioni. Il layout e il design dovranno essere implementati dal lato dell'azienda, ma CityFALCON può fornire dati NLU strutturati come base di questo componente.
Solo un esempio di un'analisi ad hoc della forza di un trend potrebbe essere visualizzato nella forza delle parole impiegate. Se tutti i titoli dicono "andare alla deriva", "lotta" e "fluttuare più in basso", sai che la situazione non è così grave come se dicessero tutti "tuffo", "implosione" e "decimato". Utilizzando CityFALCON NLU, questo tipo di analisi al volo diventa semplice come osservare tutte le istanze di un prezzo_movimento tag in un insieme di testi.
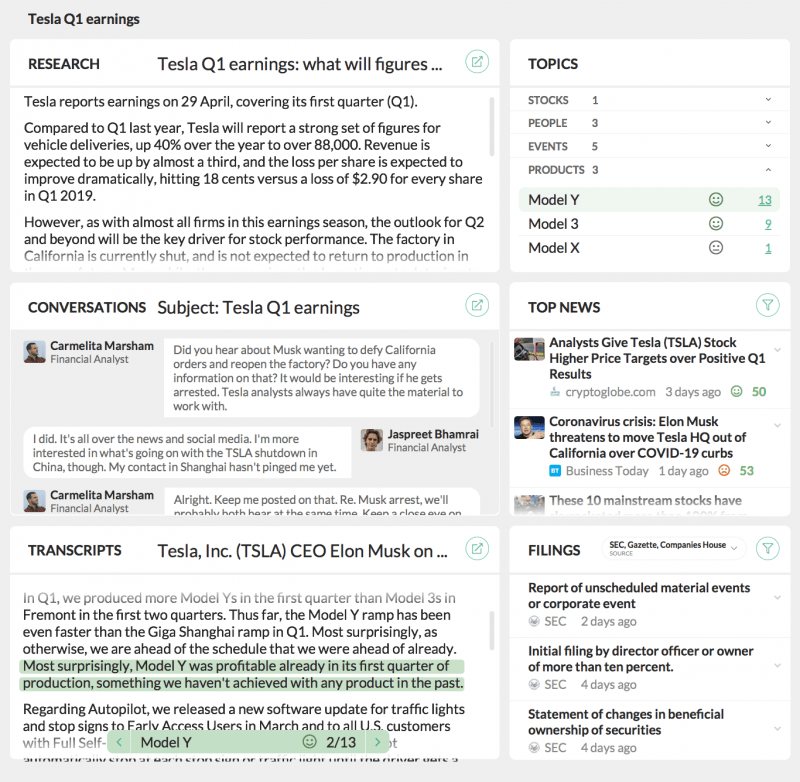
Un dashboard per potenziali dipendenti di contenuti interni ed esterni
Perché pagare per il servizio?
Alcuni potrebbero obiettare che costruire questi sistemi stessi è facile o richiede poche risorse. Alcuni potrebbero tentare di esternalizzare l'etichettatura e l'organizzazione a manodopera estera a basso costo, mentre altri potrebbero tentare di assumere alcuni sviluppatori per farlo internamente. Tuttavia, nessuna di queste soluzioni risolve adeguatamente il problema e perde un valore aggiunto molto importante.
Innanzitutto, l'enorme volume di contenuti potrebbe non essere elaborabile dagli esseri umani, quindi l'elaborazione manuale non è applicabile. Inoltre, non è possibile applicare l'estrazione NLU manuale alle chat e ad altre fonti in continua evoluzione in tempo reale. È possibile con l'apprendimento automatico e i sistemi automatizzati.
In secondo luogo, questi sistemi richiedono molto tempo per essere costruiti e implementati. Non solo gli algoritmi hanno bisogno di formazione, ma devono essere testati e adattati. L'intero sistema può richiedere anni per essere costruito, mentre è possibile concedere in licenza la tecnologia proprio adesso.
In terzo luogo, la "comprensione" sottostante e la struttura dell'intero apparato devono adattarsi man mano che nuove idee e concetti vengono al mondo. Negli affari e nella politica, ci sono costantemente nuove persone, aziende, leggi ed eventi che devono essere monitorati. Avresti bisogno di un intero team per tenere traccia di tutto questo e aggiornare gli algoritmi di conseguenza - fortunatamente, CityFALCON lo fa già per te con il nostro team di analisti finanziari multilingue.
Questi sistemi possono essere costruiti e mantenuti internamente? Sì. Tuttavia, la loro costruzione e la successiva manutenzione diventano rapidamente costose e dispendiose in termini di tempo, soprattutto in aree in rapida evoluzione come la finanza, gli affari e la politica. CityFALCON può gestire i dettagli tecnici. Ti concentri sul cliente e sul business.
In definitiva, il valore sta nei dati. Con il prodotto CityFALCON, il valore latente può essere estratto da fonti di testo finanziarie ed economiche e incanalato in attività generatrici di entrate come il trading e la gestione del portafoglio. Possiamo aiutarti ad arricchire i tuoi metadati fino alle parole nelle frasi, collegare le singole entità alle informazioni associate e creare connessioni di tipo web tra tutte le parti della tua attività.
Sicurezza e riservatezza
Poiché la sicurezza e la riservatezza sono fondamentali quando si tratta di documentazione interna o corrispondenza privata tra clienti e dipendenti, il nostro sistema garantisce che i tuoi dati siano in mani sicure.
Evitando i dettagli tecnici, tutto il testo che invii verrà inviato attraverso un normale tunnel crittografato HTTPS, quindi nessuno può leggere i dati della richiesta che invii. Quindi, sui nostri server, i tuoi dati risiedono temporaneamente nella RAM mentre vengono elaborati. Una volta elaborati, ogni traccia dei tuoi dati scompare dal nostro sistema. Ciò significa che il testo non viene mai scritto su disco o archiviato nel nostro database.
Se qualcuno hackera i nostri sistemi o un dipendente disonesto cerca di vendere informazioni sui clienti, non ci sono dati da rubare. I contenuti passati sono stati irrimediabilmente cancellati. L'unico inconveniente è che la tua richiesta non è memorizzata nella cache, quindi se devi estrarre nuovamente dallo stesso set di testo, forse è stato cancellato accidentalmente su un computer interno, dovrai ritrasmetterlo. Tuttavia, la necessità di rielaborare un documento è piuttosto rara.
Al contrario, per coloro che vogliono davvero mantenere le cose locali, possiamo offrire un'implementazione del sistema locale con aggiornamenti regolari, quindi l'intero processo NLU può avvenire presso il sito del cliente, con i dati che non lasciano mai i propri sistemi.
Integrazione conveniente
Utilizzando la nostra API, qualsiasi azienda può ora indicizzare i propri contenuti interni dalla documentazione passata o in tempo reale. È semplice come interrogare l'endpoint API per l'estrazione di entità (tagging NLU) e autorizzare te stesso con la chiave univoca della tua azienda. Naturalmente, dovrai creare la tua dashboard e interfaccia per i tuoi utenti, ma ci occuperemo di tutto il lavoro pesanteng in NLU: questo è il servizio che forniamo, dopo tutto.
Contattaci per organizzare una dimostrazione e discutere potenziali casi d'uso, limiti di chiamata e qualsiasi altra domanda tu possa avere.
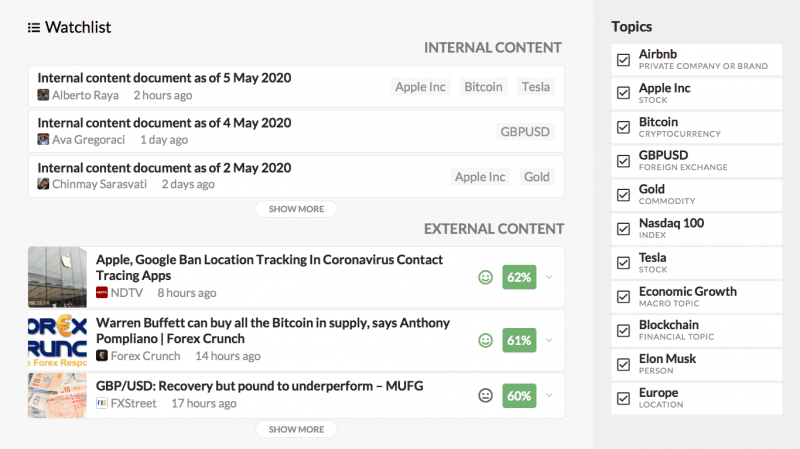
Una vista interna più semplice con una watchlist associata
Lascia un commento