


Quest'anno è stato entusiasmante in termini di nuove versioni e il prodotto CityFALCON sta davvero prendendo forma con analisi, più fonti e più servizi in arrivo online nella prima metà del 2020. Molti dei servizi e delle funzionalità API sono davvero molto potenti e lo sforzo di ricerca e sviluppo dietro di loro è stato considerevole. Per questo motivo, la maggior parte delle nuove funzionalità ha i propri post sul blog, in modo da poterle comprendere più a fondo. Questo post è semplicemente per presentarvi ciò che abbiamo realizzato finora quest'anno.
Se vuoi vedere cosa abbiamo fatto dal lato del consumatore nella prima metà del 2020, dai un'occhiata al CityFALCON 2020 Aggiornamenti al dettaglio post.
Archivi da LSE, Companies House, Gazette e altro
Verso l'inizio di quest'anno, abbiamo iniziato a servire i depositi della Borsa di Londra (LSE) e della Companies House nel Regno Unito. Da allora abbiamo aggiunto The Gazette e stiamo per aggiungere i documenti della SEC negli Stati Uniti. Riceviamo già i dati e siamo impostati sul nostro ambiente di staging, ma abbiamo bisogno di più tempo per inviare i documenti SEC all'ambiente di produzione.
Abbiamo pubblicato un post completo sul blog sul rilascio dei nostri documenti. Per ora sono disponibili solo tramite l'API, ma presto li aggiungeremo al sito Web e alle app mobili.
Estrazione NLU
Un'altra caratteristica molto preziosa per le imprese è il nostro servizio di estrazione NLU. Ancora una volta, questo lo ha garantito proprio post sul blog.
Abbiamo costruito il servizio per gran parte della vita di CityFALCON e lo stavamo utilizzando internamente per estrarre entità dal testo. Ad esempio, estraiamo algoritmicamente Amazzonia da un titolo e contrassegnalo come azienda per quel contenuto.
Combinando questo con il nostro database gerarchico, le informazioni risultanti possono essere molto illuminanti. Abbiamo il ticker di Amazon, i loro numeri IRS e SEC e la loro struttura di settore, settore e sottosettore associato.
Ora le aziende possono utilizzare questo servizio e i dati strutturati sui propri contenuti interni, come memo, chat, e-mail e report interni. Vedere il post del blog sopra per un trattamento più approfondito. Forniamo l'estrazione di entità NLU come servizio autonomo per l'indicizzazione dei contenuti interni, quindi le aziende che si iscrivono non hanno bisogno di acquistare altri pacchetti API se non ne hanno bisogno.
Di seguito è riportato un esempio della risposta JSON per un semplice messaggio inviato tra due dipendenti, che fornisce molte informazioni per le aziende.
Risposta JSON per messaggio informale tra due dipendenti“testo”: “pensi che gli Stati Uniti avvieranno un'indagine contro Facebook”,
“lang”: “it”,
“tag”: [
{
“inizio”: 14,
“fine”: 16,
"valore": "USA",
“tipo”: “posizione”,
“corrispondente”: vero,
"entità": [
{
“nome”: “Stati Uniti d'America”,
“tipo”: “geo_regioni”,
"metadati": {
"Paesi": [
"Stati Uniti d'America"
],
“subcontinenti”: [
“Nordamerica”
],
“continenti”: [
"Nord America"
]
}
}
]
},
{
“inizio”: 51,
“fine”: 59,
“valore”: “Facebook”,
“tipo”: “azienda”,
“corrispondente”: vero,
"entità": [
{
“nome”: “Facebook Inc”,
“tipo”: “azioni”,
"metadati": {
"ID_legali": [
“0201665019_irs-us”,
“0001326801_sec-us”
],
"ticker": [
"FB_US"
],
“categorie”: [
"Social Media"
],
“sottosettori”: [
"Servizi e infrastrutture Internet"
],
“industrie”: [
"Servizi IT"
],
“settori”: [
"Tecnologia",
“Comunicazioni”
]
}
}
]
},
{
“inizio”: 22,
“fine”: 42,
“valore”: “avvio indagine”,
“tipo”: “evento”,
“corrispondente”: falso
}
]
}
Ticker e numeri legali raccolti dal servizio NLU possono essere inseriti nel servizio di archiviazione per automatizzare molte attività. Un potenziale dashboard interno che estrae le entità e poi scorre nel recupero di archivi, ricerche e contenuti di notizie potrebbe avere il seguente aspetto:
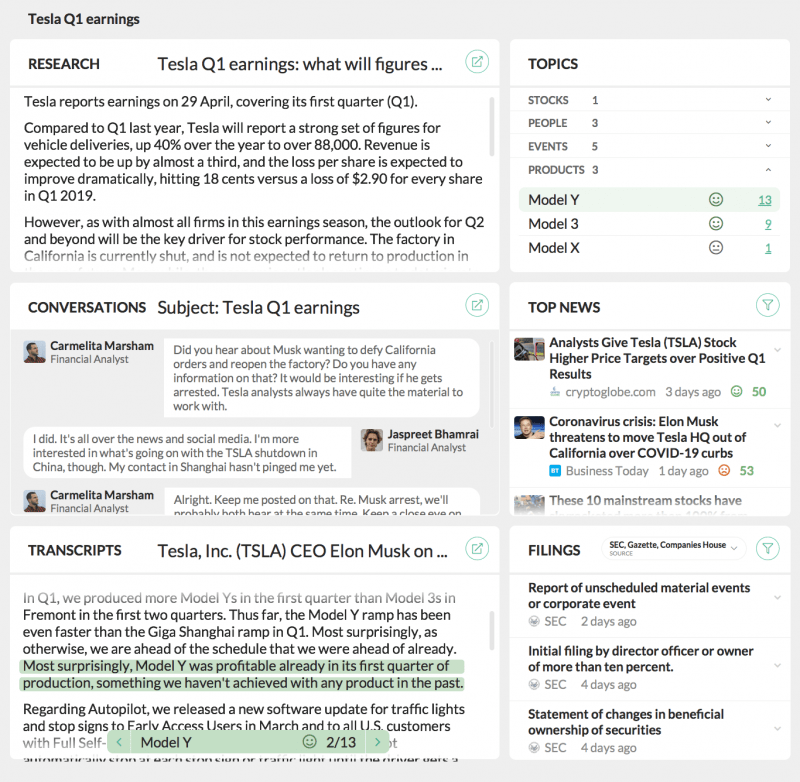
Una potenziale applicazione interna per assistere i dipendenti nelle loro ricerche e operazioni
Storie simili Raggruppamento in 16 lingue
Similar Stories utilizza l'apprendimento automatico avanzato e proprietario per confrontare ogni singolo contenuto che riceviamo per somiglianza, tra cui notizie, tweet e rapporti. Ogni pezzo di contenuto viene confrontato con ogni altro pezzo utilizzando 512 dimensioni, come autore e posizione. Naturalmente, con oltre 500 dimensioni, alcune possono sembrare strane combinazioni e potrebbero non significare molto per gli esseri umani, ma le correlazioni che gli algoritmi dei Big Data possono tracciare potrebbero rivelare alcune sottili somiglianze.
Dopo che tutto il contenuto è stato confrontato, i gruppi vengono formati in base alla vicinanza tra loro nello spazio vettoriale di confronto per somiglianza. Quindi, AI sceglie il più rappresentativo del gruppo (il baricentro) e questa parte di contenuto viene contrassegnata come la storia principale, che viene restituita come voce di primo livello nel JSON. All'interno di ogni voce JSON di primo livello, l'altro contenuto nel gruppo rientra in contenuto_simile campo di quella voce.
Sul Web e sui dispositivi mobili, ciò consente agli utenti di saltare facilmente i contenuti ripetitivi o, al contrario, leggere varie riprese e angolazioni sullo stesso evento.
Nell'API, questa configurazione può portare a una migliore elaborazione dei vari angoli. CityFALCON ha già raggruppato il contenuto, quindi la tua azienda non ha bisogno di ricercare ed eseguire questa complicata attività NLU. Ora puoi concentrarti sul prendere decisioni con quelle informazioni simili invece di impegnare risorse cercando di costruire la tecnologia NLU: l'abbiamo già sviluppata per te. Se la tua applicazione prevede la fornitura di contenuto agli utenti finali, puoi rimuovere tutte le storie simili e visualizzare solo le voci JSON principali (ad esempio, storie univoche), in modo che beneficino della stessa riduzione della ridondanza.
Inoltre, l'algoritmo di somiglianza funziona in 16 lingue. Un caso d'uso sarebbe quello di catturare sfumature per i team bilingue per analizzare e ottenere informazioni sul processo di pensiero e sui potenziali risultati degli eventi, in base a chi sta scrivendo cosa e quando.
Analisi del sentimento
Questa è un'altra caratteristica così preziosa che abbiamo scritto un intero post sul blog sull'analisi del sentiment.
L'analisi del sentiment è una potente analitica che sfrutta l'NLU per assegnare un punteggio ai contenuti in base a quanto sia positivo, negativo o neutro il suo linguaggio. I nostri sistemi suddividono il contenuto a livello di clausola, quindi anche una singola frase può avere più di un punteggio di sentiment associato (uno per ogni clausola).
Inoltre, utilizzando il nostro servizio di estrazione di entità NLU (internamente, ovviamente), possiamo identificare quale delle nostre 300.000 entità nel nostro database è associata al contenuto in questione. Quindi creiamo punteggi aggregati per tutte le sedi, le persone, le aziende, le azioni, le organizzazioni e altri tipi di entità nel database.
Anche i gruppi aggregati, come i settori (un'aggregazione di tutte le società costituenti), ottengono i propri punteggi. I punteggi per i gruppi aggregati sono medie ponderate, quindi mentre CityFALCON è nel settore tecnologico insieme a Microsoft e IBM, questi due generalmente hanno molto più peso di CityFALCON perché ottengono molta più attenzione da parte dei media.
Una panoramica semplificata del sistema può essere simile a questa:
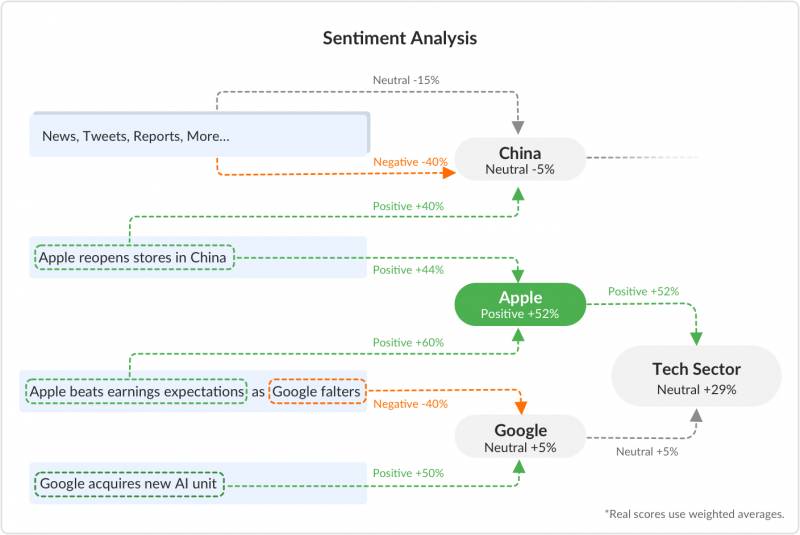
Una panoramica semplificata delle connessioni dell'analisi del sentiment
Attraverso l'API, questi dati vengono forniti insieme a entità e contenuti (notizie). Una risposta JSON ben formattata (abbastanza stampata) con sentiment potrebbe essere simile a questa:
Aggiunta del campo ID legale per la ricerca
In precedenza l'API accettava solo risorse, ticker, e full_ticker come campi di input per trovare aziende, persone e altri target delle informazioni richieste. Ora, gli utenti dell'API possono cercare per id_legale, anche. Ciò rende l'integrazione più standardizzata e precisa. Inoltre, è più facile prendere di mira le aziende private che non hanno ticker. Ad esempio, Revolut nel Regno Unito è un'azienda molto popolare da tenere d'occhio, ma non ha un ticker standard per identificarla. Con il id_legale campo, ora gli utenti dell'API possono scegliere come target 08804411_companieshouse-it per recuperare informazioni su Revolut.
Vedi il base di conoscenza per ulteriori tutorial e spiegazioni o dai un'occhiata al documentazione per provarlo nella sandbox.
Accesso API personale
Abbiamo anche aperto l'API per uso personale. Abbiamo visto l'interesse di sviluppatori e persone che volevano creare le proprie applicazioni finanziarie e aziendali utilizzando i nostri dati, ma non erano in grado di acquistare abbonamenti API completi.
Gli individui possono ora utilizzare l'API per effettuare fino a 10.000 chiamate al mese e recuperare i dati della storia, il titolo, la descrizione e il punteggio CityFALCON.
Un abbonamento personale parte da $20 al mese per gli utenti del mondo accademico, sanitario e no profit o $40 al mese per tutti gli altri. Presto arriverà una versione Premium che offre più funzionalità e un limite di chiamate più elevato.
Maggiori dettagli sono nel post di blog dedicato sull'accesso API personale.
Soggetti Interessati e Seconda Semestrale
Finora quest'anno abbiamo rilasciato alcune funzionalità importanti per l'API e siamo fiduciosi nella posizione della nostra azienda per rilasciarne altre in futuro. Siamo orgogliosi di ciò che abbiamo realizzato fino ad oggi e siamo entusiasti di raccogliere i frutti di anni di ricerca e sviluppo nella scienza dei dati, nelle infrastrutture e nella cura dei dati finanziari.
Aggiungiamo costantemente nuove fonti di contenuto e continuiamo il nostro Progetto di ricerca e sviluppo a Malta per espandere la nostra copertura linguistica, sia dal punto di vista dei contenuti che nelle applicazioni di machine learning. Ulteriori servizi di machine learning per i dati interni sono all'orizzonte.
Se sei interessato a qualsiasi servizio API, fallo Contattaci per una consultazione e una dimostrazione. Quanto meglio conosciamo il tuo caso d'uso e la tua situazione, tanto migliore sarà il prodotto che possiamo fornirti.
Lascia un commento