


Представьте себе сценарий: 75 000 документов и тонны новостей, исследований и сообщений чата, которые нужно отсеивать, отмечать и классифицировать, без какой-либо заметной закономерности в их последовательности. Вы хотите отсортировать их по компании и по местоположению, но без тегов верхнего уровня, постраничных и отдельных предложений задача кажется почти невыполнимой. Является ли 14 198-й документ макроэкономическим отчетом о Северной Америке, Китае, Токио или взаимодействием всех трех? 47 938-й документ обсудить дивиденды, прибыль или запуск нового продукта? Относится ли это клиентское письмо от 6 месяцев назад к Google, Alphabet или GOOG? Хуже того, некоторые наборы текста могут занимать сотни страниц и содержать много разных тем и фрагментов важных данных. Заголовки, оглавления и теги верхнего уровня могут рассказать вам не так много.
Вы мог нанять людей, чтобы они вручную читали, понимали и систематизировали каждый документ, электронную почту, новость и сообщение чата. К сожалению, это требует значительных затрат времени и финансовых ресурсов, а поскольку количество журналов чатов, электронных писем, новостных статей и отчетов растет с каждым днем, в любом случае может оказаться невозможным фактически проиндексировать весь контент, используя человеческие глаза и умы. Сообщения между сотрудниками одного отдела могут оказаться очень полезными для сотрудников другого, но большинство компаний позволяют этим данным исчезать в почтовых ящиках сотрудников, где их потенциал использования теряется в пустоте.
Лучшее решение - управляемый машинным обучением системы понимания естественного языка (NLU), которые автоматизируют найти, идентифицировать и пометить процесс, результатом которого являются «помеченные объекты» или «извлеченные объекты». NLU - это более широкий подход к традиционной обработке естественного языка (NLP), пытающийся понять вариации текста как представляющие одну и ту же семантическую информацию (значение). После извлечения сущностей до уровня предложения можно выполнять все виды текстовая аналитика, например тепловые карты и группировки, которые позволяют получить полезные сведения. Анализ тональности - еще один очень популярный метод текстовой аналитики, используемый для понимания больших корпусов (агрегированных наборов) текста.
В CityFALCON мы только что запустили систему извлечения сущностей NLU и анализ настроений, настроенную специально для делового, финансового и политического контента на нескольких языках для идентифицированных сущностей и для целых документов, новостей, журналов чатов и цепочек электронной почты.
Необходимость
Есть несколько причин для идентификации и маркировки продуктов, компаний, людей и других тем в тексте. Одна из причин заключается в том, что у правительств есть требования к хранению документов, а у некоторых компаний есть очень большие наборы хранимых документов, которые не систематизированы и не используются для дальнейшего анализа больших данных.
Другие компании просто сохраняют все свои сообщения и внутренние документы для дальнейшего использования или для анализа больших данных. Если текст сгенерирован внутри компании, возможно, на них есть несколько тегов, но они не очень глубоко описывают содержимое внутри. Если текст создан извне, например новостной контент, теги могут быть недостаточными, неточными или отсутствовать.
В любом случае, только ограниченное понимание текста может быть получено из тегов верхнего уровня, заголовков разделов и резюме разделов. Метаданные существуют на всех слоях текста, и NLU может помочь лучше понять отдельные документы, а также весь корпус. Поскольку NLU работает так же детально, как и уровень предложения, документы можно анализировать алгоритмически по предложениям, а вывод обрабатывать для получения мощного понимания.
Одно из обещаний больших данных - обрабатывать объемы информации, которые отдельные люди или их группы просто не могут. Поскольку наш человеческий разум может одновременно удерживать в себе столько информации, а общение между людьми ограничено тем, насколько быстро мы можем передавать мысли с помощью языка, понимание трех миллионов страниц новостей, документации и электронных писем не является подвигом для человека. или даже команда. Это для машин, чтобы превратить их в гораздо более управляемые части.
NLU и соответствующая аналитика помогают компаниям организовать свой контент, сделать его более доступным для поиска по ключевым словам и могут предложить идеи, которые человеческий разум просто не может синтезировать (хотя мы, конечно, можем понять результат).
Таким образом, везде, где необходимо организовать, классифицировать и понять большие объемы текстовой информации с высоким разрешением, система NLU CityFALCON может легко обеспечить понимание и межотраслевой анализ.
Как это устроено
На высоком уровне наш недавно запущенный API разбивает любой набор текста на составляющие предложения, а затем идентифицирует все сущности в каждом предложении. Например, возьмем недавний заголовок:
Фондовые фьючерсы падают вслед за доходами, угроза Трампа пошлинам Китая из-за пандемии
Какие наши системы разделятся следующим образом:
Акции = финансовый инструмент
Фьючерсы = финансовый инструмент
Заработок = событие
Трамп = человек
Китай = расположение
Тарифы = financial_topic
Пандемия = financial_topic
И если вы хотите увидеть ответ JSON полностью, мы разместили его здесь для вас.
{«Text»: «Фьючерсы на акции падают вслед за доходами, угроза Трампа для Китая тарифами из-за пандемии»,
«Lang»: «en»,
«Теги»: [
{
«Начало»: 0,
«Конец»: 5,
«Value»: «Акция»,
«Тип»: «финансовый_инструмент»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Акции»,
«Type»: «topic_classes»,
«Метаданные»: {}
}
]
},
{
«Начало»: 6,
«Конец»: 13,
«Значение»: «фьючерс»,
«Тип»: «финансовый_инструмент»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Фьючерсы»,
«Type»: «financial_topics»,
«Метаданные»: {}
}
]
},
{
«Начало»: 25,
«Конец»: 33,
«Ценность»: «прибыль»,
«Тип»: «событие»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Прибыль»,
«Type»: «major_business_and_related_activities»,
«Метаданные»: {}
}
]
},
{
«Старт»: 36,
«Конец»: 43,
«Value»: «Трамп»,
«Тип»: «человек»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Семья Трампа»,
«Тип»: «люди»,
«Метаданные»: {}
}
]
},
{
«Начало»: 55,
«Конец»: 60,
«Значение»: «Китай»,
«Тип»: «местоположение»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Китай»,
«Тип»: «гео_регионы»,
«Метаданные»: {
«Страны»: [
"Китай"
],
«Субконтиненты»: [
«Восточная Азия»
],
«Континенты»: [
«Азия»
]
}
}
]
},
{
«Начало»: 61,
«Конец»: 68,
«Стоимость»: «тарифы»,
«Type»: «financial_topic»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Тарифы»,
«Type»: «financial_topics»,
«Метаданные»: {}
}
]
},
{
«Старт»: 74,
«Конец»: 82,
«Значение»: «пандемия»,
«Type»: «financial_topic»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Пандемия»,
«Тип»: «другие_темы»,
«Метаданные»: {}
}
]
}
]
}
Далее берем сущность Китай. Поскольку он был «сопоставлен» в нашей базе данных, с ним также связана иерархия. Это означает термин Китай теперь может быть возвращен, когда кто-то ищет Восточную Азию или Азию, что позволяет намного лучше индексировать внутренний контент.
В дополнение к иерархиям сопоставленные объекты могут объединять несколько имен вместе. Одним из таких примеров является термин «Коронавирус», который будет сопоставлен в наших системах с «COVID-19», «covid19» и «covid» среди многих других связанных слов и коротких фраз. Это позволяет сотруднику искать один термин и получать любые связанные элементы, даже если простой текстовый поиск завершится неудачно, потому что простой текстовый поиск COVID-19 не будет возвращать упоминания о Коронавирус.
Давайте посмотрим на другой пример. Это может быть сообщение в чате между сотрудниками:
- Вы думаете, США начнут расследование в отношении Facebook?
Опять же, вот JSON, возвращаемый нашими системами.
{
«Text»: «вы думаете, что США начнут расследование против Facebook»,
«Lang»: «en»,
«Теги»: [
{
«Начало»: 14,
«Конец»: 16,
«Значение»: «США»,
«Тип»: «местоположение»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Соединенные Штаты Америки»,
«Тип»: «гео_регионы»,
«Метаданные»: {
«Страны»: [
"Соединенные Штаты Америки"
],
«Субконтиненты»: [
«Северная Америка»
],
«Континенты»: [
"Северная Америка"
]
}
}
]
},
{
«Начало»: 51,
«Конец»: 59,
«Value»: «Facebook»,
«Тип»: «компания»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Facebook Inc»,
«Тип»: «акции»,
«Метаданные»: {
«Legal_ids»: [
«0201665019_irs-us»,
«0001326801_sec-us»
],
«Тикеры»: [
«FB_US»
],
«Категории»: [
"Социальные медиа"
],
«Подотрасли»: [
«Интернет-услуги и инфраструктура»
],
«Отрасли»: [
«ИТ-услуги»
],
«Секторы»: [
"Технологии",
«Связь»
]
}
}
]
},
{
«Начало»: 22,
«Конец»: 42,
«Value»: «начать расследование»,
«Тип»: «событие»,
«Соответствует»: ложь
}
]
}
Здесь «США» - это согласованная сущность, которая также содержит иерархию. Конкретная тема Соединенные Штаты Америки будет идентифицироваться с «США», «Соединенные Штаты» и «Америка», и его также можно будет найти при поиске в Северной Америке. Поэтому, когда сотрудник смутно помнит цепочку разговора об «Америке», его не расстроит несоответствие между поисковым запросом «Америка» и фактическим используемым термином «США». При обычном текстовом поиске попытка найти беседу может потерпеть неудачу.
Компании также являются частью иерархии в экономике, и поиск ИТ-услуг обеспечит включение «Facebook» в результаты. Не только это, но и потому, что Facebook является публичной компанией, возвращаются ее юридические идентификационные номера, включая идентификатор SEC и тикер (а) по странам. Это может быть связано с документами компании или программно введено в другой алгоритм, который извлекает SEC документы из CityFALCON или использоваться для перекрестных ссылок на судебные дела в судебной системе США.
Наконец, также может быть полезно выбрать действия из любого разговора или исследовательского отчета. Формулировка начать расследование был подобран нашим машинное обучение системы как событие. Эти данные помогают определить тему текста, и хорошим вариантом использования будет пометка сообщений электронной почты их событиями. В этом примере событие было не сопоставлены, но в CityFALCON есть десятки тысяч событий, которые сопоставлены таким же образом, как местоположения и компании могут быть сопоставлены с соответствующими данными.
Поскольку машинам безразлично, есть ли у вас 1 или 100 000 предложений, этот процесс можно повторять бесконечно для корпуса любого размера. Все это будет обработано за несколько секунд, а наш алгоритм обработает их на быстром графическом процессоре.
Область применения системы CityFALCON
Мы определяем 20 групп настраиваемых сущностей и более 300 000 тем «именованных организаций», связанных с финансами, добавляя глубокий уровень возможного анализа для банков, правительств, научных кругов и других пользователей, которым требуется анализ контента на основе экономических и финансовых условий, помимо продуктов конкурентов, таких как IBM или Microsoft, чьи системы предназначены для общего содержания.
Например, одна тема охватывает идею «Соединенные Штаты Америки», где связанные имена, такие как «США», «Америка» и «США», считаются частью этой одной темы, как и метаданные (для местоположения это географическая иерархия). Все темы содержат связанную информацию и, если они доступны, иерархии и соответствующие имена. Они варьируются от местоположений до людей и компаний и продуктов, и вы даже можете просматривать их в нашем Каталог если вы хотите увидеть их все. С помощью API вы сможете таким же образом индексировать свой собственный контент, и эта возможность является огромным резервуаром организаторской силы.
Со всеми этими темами и группами сущностей NLU как познавательный инструмент превращает поиск из инструмента, который укрепляет идею, уже присутствующую в уме, в инструмент, который строит идеи, основанные на концепциях. Вместо поиска в конкретном документе или цепочке писем Биотехнологии, рабочие могут искать теги секторов. Возможно, наряду с биотехнологиями часто упоминается и другой сектор, который служит источником потенциального понимания. И наоборот, кто-то может захотеть найти все движения цен в цепочке электронной почты или в наборе из 15000 новостных сообщений, независимо от направления и конкретного используемого словаря (всплеск, шип, прыжок, ракета, взлет, и т.д.).
На момент публикации этого сообщения в блоге системы CityFALCON готовы принимать контент на английском и русском языках. Этим летом будут приняты украинский и испанский языки, и будут добавлены другие языки по мере разработки наших систем На Мальте реализуется научно-исследовательский проект, который включает китайский, японский, корейский, немецкий, французский, португальский и другие языки. В конце концов, мы охватим более 90 языков.
NLU для внутреннего контента
Ядро CityFALCON - это NLU: мы собираем, объединяем и обрабатываем финансовые новости и контент - понимаем их язык - и доставляем их пользователям в режиме реального времени. Мы добавляем некоторую аналитику сверху, например оценку релевантности, настроения и некоторые другие идеи, находящиеся в стадии разработки.
Этот огромный механизм понимания, в первую очередь, финансового и экономического языка хорошо работает со всеми данными, которые мы получаем сами. Он будет работать так же хорошо с клиентскими текстовыми данными, будь то собственные исследования, экономические отчеты, расшифровки телефонных разговоров о доходах или простые внутренние заметки и электронные письма.
Наш проприетарный механизм NLU готов к использованию клиентами для индексации и организации своего собственного контента. Механизм NLU был усовершенствован нашей командой финансовых аналитиков и аналитиков NLU в течение последних трех лет для новостных статей, твитов и нормативных документов. Теперь эту возможность можно применить к внутреннему финансовому контенту, который вы хотите проиндексировать.
Портал потенциального сотрудника может отображать следующие компоненты.
Внешний контент
Мы предоставляем этот контент из более чем 5000 источников и Twitter. Мы будем отправлять вам новости, твиты, финансовые отчеты и нормативные документы, оценку релевантности CityFALCON, данные NLU внешнего контента и анализ настроений.
Внутренний контент
Это происходит из любого текста, предоставленного клиентом, например из внутренней переписки, публикаций и неформальной электронной почты между отделами.
Межорганизационный контент
Некоторые из возвращенных тегов содержат не только имена, но и важную информацию, такую как положение в экономических иерархиях, таких как секторы и подотрасли, а также юридическую информацию, такую как идентификационные номера компаний и тикеры. Это может дополнительно расширить возможности вашего поиска или автоматизировать некоторые процессы, например, получение последней котировки акций с биржи для ваших трейдеров.
Чат в реальном времени
Разговоры сотрудников помечаются тегами по мере их возникновения, что дает возможность поиска информации, например, как часто команда упоминает сектор или ключевого человека в течение рабочей недели. Это позволяет лицам, принимающим решения, обнаруживать неясную, но полезную информацию. Если все болтают о X, то X может стать следующим большим шагом на рынке.
Это также дает сотрудникам возможность просматривать прошлые темы чата и выполнять поиск по сущности или группе сущностей, а не по конкретному ключевому слову, что расширяет возможности для установления связей. Например, кто-то может захотеть узнать все случаи, когда конкретный коллега упоминает «финансовый_инструмент» или «компанию», независимо от специфики.
Чат в реальном времени может даже вести ленту новостей в реальном времени, которая адаптируется к текущей теме разговора.
Визуализации
Этот компонент позволяет сразу понять структуру и темы набора текстов, будь то цепочки писем с клиентами, новости недели или протоколы встреч. Макет и дизайн должны быть реализованы на стороне компании, но CityFALCON может предоставить структурированные данные NLU в качестве основы для этого компонента.
Только один пример специального анализа силы тренда может быть визуализирован по силе используемых слов. Если все заголовки говорят «спускаться вниз», «бороться» и «плавать ниже», вы знаете, что ситуация не так плоха, как если бы все они говорили «нырять», «взорваться» и «уничтожить». Используя CityFALCON NLU, этот вид анализа на лету становится таким же простым, как просмотр всех экземпляров price_movement тег в наборе текстов.
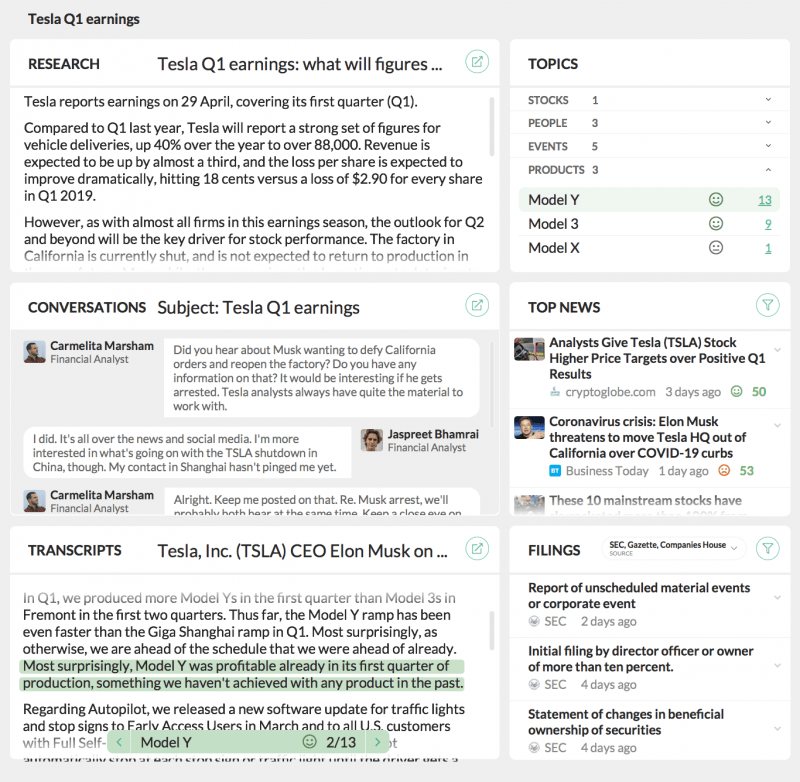
Панель мониторинга потенциального сотрудника внутреннего и внешнего контента
Зачем платить за услугу?
Некоторые могут возразить, что построить эти системы сами по себе легко или мало ресурсов. Некоторые могут попытаться передать теги и организацию на аутсорсинг дешевой зарубежной рабочей силе, в то время как другие могут попытаться нанять нескольких разработчиков, чтобы сделать это внутри компании. Однако ни одно из этих решений не решает проблему адекватно, и они упускают очень важную добавленную стоимость.
Во-первых, огромный объем контента может быть недоступен для обработки людьми, поэтому ручная обработка неприменима. Кроме того, невозможно применить ручное извлечение NLU для чатов и других постоянно меняющихся источников в режиме реального времени. Это возможно с машинным обучением и автоматизированными системами.
Во-вторых, создание и внедрение этих систем занимает много времени. Алгоритмы не только нуждаются в обучении, их нужно тестировать и настраивать. На создание всей системы могут уйти годы, в то время как технологию можно лицензировать. прямо сейчас.
В-третьих, лежащее в основе «понимание» и структура всего аппарата должны адаптироваться по мере появления в мире новых идей и концепций. В бизнесе и политике постоянно появляются новые люди, компании, законы и события, которые необходимо отслеживать. Вам понадобится целая команда, чтобы отслеживать все это и соответствующим образом обновлять алгоритмы - к счастью, CityFALCON уже делает это за вас с нашей многоязычной командой финансовых аналитиков.
Можно ли построить и поддерживать эти системы внутри компании? Да. Однако их строительство и последующее обслуживание быстро становятся дорогостоящими и требуют много времени, особенно в быстро развивающихся областях, таких как финансы, бизнес и политика. CityFALCON может разобраться в технических деталях. Вы ориентируетесь на клиента и бизнес.
В конечном итоге ценность заключается в данных. С помощью продукта CityFALCON скрытая стоимость может быть извлечена из финансовых и экономических текстовых источников и направлена на такие приносящие доход мероприятия, как торговля и управление портфелем. Мы можем помочь вам обогатить ваши метаданные до слов в предложениях, связать отдельные объекты с связанной информацией и построить сетевые связи между всеми частями вашего бизнеса.
Безопасность и конфиденциальность
Поскольку безопасность и конфиденциальность имеют первостепенное значение, когда речь идет о внутренней документации или частной переписке между клиентами и сотрудниками, наша система гарантирует, что ваши данные будут в надежных руках.
Избегая технических деталей, весь текст, который вы отправляете, будет отправлен через обычный зашифрованный туннель HTTPS, поэтому никто не сможет прочитать данные запроса, которые вы отправляете. Затем на наших серверах ваши данные временно находятся в оперативной памяти во время обработки. После обработки все следы ваших данных исчезнут из нашей системы. Это означает, что текст никогда не записывается на диск и не сохраняется в нашей базе данных.
Если кто-то взломает наши системы или ненадежный сотрудник попытается продать информацию о клиенте, у вас не будет данных, которые можно было бы украсть. Прошлый контент был безвозвратно стёрт. Единственным недостатком является то, что ваш запрос не кэшируется, поэтому, если вам нужно повторно извлечь из того же набора текста - возможно, он был случайно удален на внутреннем компьютере - вам нужно будет повторно передать его. Однако необходимость в повторной обработке документа возникает довольно редко.
И наоборот, для тех, кто действительно хочет, чтобы вещи оставались локальными, мы можем предложить развертывание локальной системы с регулярные обновления, поэтому весь процесс NLU может происходить на стороне клиента, при этом данные никогда не покидают свои собственные системы.
Удобная интеграция
Используя наш API, любая компания теперь может индексировать свой внутренний контент из прошлой документации или в режиме реального времени. Это так же просто, как запрос конечной точки API для извлечения сущностей (тегирование NLU) и авторизация с использованием уникального ключа вашей компании. Конечно, вам нужно будет создать свою собственную панель управления и интерфейс для своих пользователей, но мы возьмем на себя всю тяжелую работу.ng в NLU - в конце концов, это наша услуга.
Связаться с нами чтобы организовать демонстрацию и обсудить возможные варианты использования, ограничения на количество звонков и любые другие вопросы, которые могут у вас возникнуть.
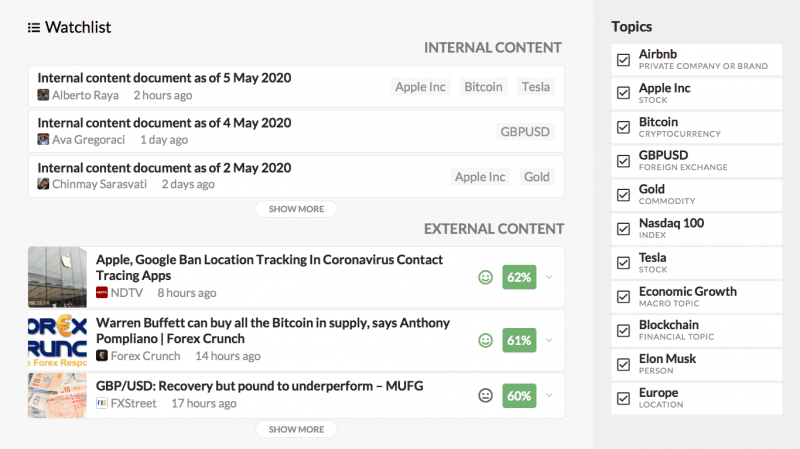
Более простой внутренний вид со связанным списком наблюдения
Добавить комментарий