


В то время как большинство компаний стремятся монополизировать внимание своих пользователей, мы в CityFALCON стараемся снизить бремя внимания, чтобы пользователи могли более эффективно и действенно участвовать в рынках. Группа похожих историй делает шаг в этом направлении, поэтому пользователи могут тратить меньше времени на должную осмотрительность и больше времени на принятие решений, общение с друзьями и семьей и выполнение своих хобби.
Каждый раз, когда происходит крупное событие, как традиционные, так и социальные сети освещаются отчетами, твитами и сообщениями о событиях. В международных случаях они также обычно публикуются на нескольких языках. Большинство репортажей, особенно когда появляются самые свежие новости, могут быть короткими статьями, в которых рассказывается очень похожие основные факты. Со временем появляется все больше информации, и объем информации увеличивается, в результате чего источники новостей немного расходятся в своих взглядах. Тем не менее, основная идея новостных платформ, как правило, остается очень похожей - при условии, что фальшивые новости не представлены.
Это соответствие может привести к потере драгоценного времени на исследования и комплексную проверку, потому что истории повторяют одну и ту же информацию. Благодаря группировке похожих историй CityFALCON избавляет от необходимости изучать несколько похожих интерпретаций одной и той же проблемы.
С другой стороны, некоторые участники рынка опасаются упустить тонкие или скрытые ключевые различия, которые могут привести к более правильному инвестиционному решению. Такие участники ищут весь доступный аналогичный контент, чтобы лучше понять проблему (в том числе на других языках), и этот подход настоятельно рекомендуется всем, кто собирается принять финансовое или деловое решение.
Группировка похожих историй помогает этим пользователям, группируя весь этот контент в одном месте, поэтому несколько экземпляров схожей информации могут быть найдены одновременно в одном месте. Это позволяет избежать упущения из виду важных различий из-за бессистемного поиска аналогичного содержания в ленте новостей. Кроме того, когда задействовано несколько языков, CityFALCON собирает и объединяет многоязычный контент в кластеры.
Внешний вид и преимущества группировки похожих историй
Подобные истории появляются во всех каналах доставки CityFALCON: мобильных приложениях, веб-сайте и API. В предыдущих версиях нашей платформы все истории занимали свои собственные карточки историй, каждая история или твит - отдельная строка со всей связанной информацией. С очень популярными темами или при возникновении важных событий новостей, канал может быть наводнен новостной статьей за новостной статьей (и определенно твитом за твитом), сообщающим об одном и том же.
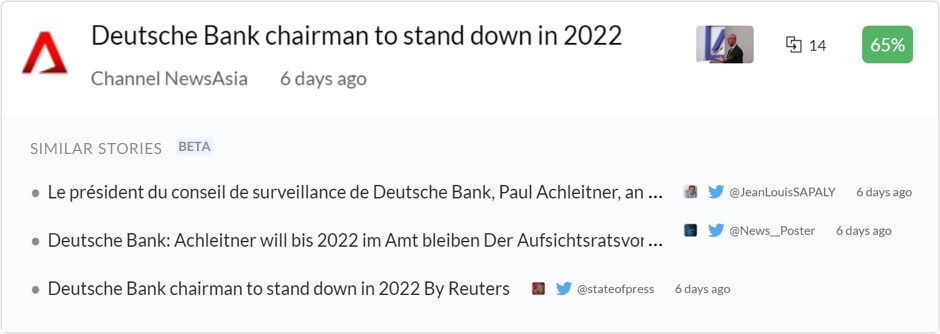
Подобные истории объединяют все эти отдельные карточки с похожим содержанием в единую карточку с репрезентативным заголовком. Подобный контент печатается на той же карточке для быстрого доступа к просмотру, но не занимает много места.
Курирование контента - запись, нравится ли вам, не нравится или считает, что истории не имеют отношения к делу - теперь также может выполняться для всего аналогичного контента за одно действие. Курирование помогает нашим машинам лучше понять ваши потребности, чтобы повысить релевантность предоставляемого вам контента. С помощью этого действия с одним щелчком для нескольких историй вы можете помочь алгоритмам учиться быстрее. Если вы хотите курировать истории индивидуально, вам нужно разгруппировать похожий контент.
В этом контексте инструмент курирования «скрыть» позволяет вам скрыть весь похожий контент, чтобы вы могли перейти к следующей идее, не сталкиваясь постоянно с информацией, которую вы уже усвоили.

Карточка похожих историй с выделенными инструментами курирования
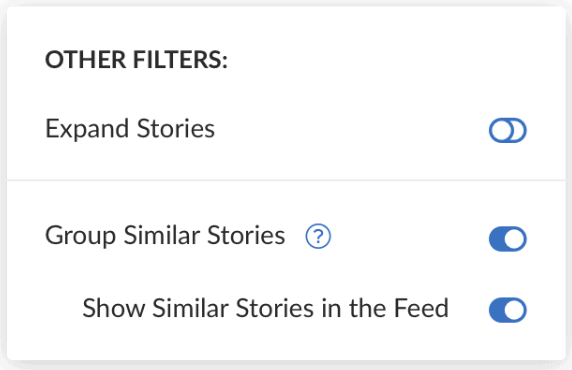
Лента новостей по умолчанию в CityFALCON теперь объединяет похожий контент в такие карточки. Если вы хотите вернуться к старому виду, просто выключите тумблер для Группировать похожий контент. В результате каждая история будет представлена на отдельной карточке в ленте.
Чтобы увидеть только наиболее репрезентативная история - то есть скрыть весь похожий контент, собранный внизу сгруппированной карточки - можно отключить Показывать похожий контент в ленте. Это полезно для просмотра новостей, не отвлекаясь на чтение слишком большого количества похожих заголовков, которые могут привлечь ваше внимание. Имейте в виду, что при этом скрывается любой контент, помеченный как «похожий», за исключением наиболее репрезентативного фрагмента контента, который будет заголовком карточки.
Короче говоря, если вы хотите просмотреть новости и прочитать много разных тем, отключите Показывать похожий контент в ленте. Если вы хотите погрузиться глубже или просто хотите, чтобы заголовки были в разных заголовках из-за их немного отличающейся интерпретации событий, оставьте включенными оба параметра для похожего контента.
Как мы это делаем
Чтобы сгруппировать истории вместе, наши алгоритмы анализируют каждый заголовок, мета-описание и, если доступно в виде полнотекстовой статьи на нашей платформе, сам рассказ. Мы также анализируем твиты. Затем, используя всю эту информацию, мы векторизуем контент и размещаем истории и твиты в кластеры. Затем, используя те же данные анализа, но другой алгоритм обработки естественного языка (NLP), мы выбираем наиболее репрезентативную историю для этой группы. Если историй по-прежнему слишком много, процесс кластеризации и выбора представителя повторяется.
Наконец, наиболее репрезентативные истории предоставляются пользователям в качестве заголовков карточек, а те, что находятся в кластере, представляются как похожие истории. Наши модели НЛП с машинным обучением значительно повышают ценность некоторых традиционных компаний, таких как Новости Google, позволяют группировать и сравнивать независимо от языка контента. Итак, если есть несколько языков, обсуждающих одну и ту же тему, CityFALCON сгруппирует их вместе, если мы поддерживаем язык для группировки. По состоянию на июнь 2020 года эта поддержка охватывает 16 языков, а к концу года - до 93.
Кластеризация и потеря информации
Использование технологий для сжатия лингвистической информации в меньший набор вызывает ряд общих вопросов. Насколько это точно? Как я узнаю, что кластеризация действительно «похожа»? Не слишком ли сжатый при таком подходе информация, поэтому я пропущу важную информацию?
Начнем с аккуратности. По крайней мере, для языков, на которых вы говорите, легко убедиться, что контент, помеченный как аналогичный действительно похоже. Вы по-прежнему можете читать заголовки и сразу проверять, похожи они или нет. Хотя машинное обучение означает, что точность не будет 100%, мы выпустили эту функцию только после того, как тестирование, обучение и доработка привели к практической точности. Даже люди не могут быть точными на 100% - а люди не могут читать 1 миллион историй и твитов в день, чтобы найти сходство, как это могут сделать наши алгоритмы. Таким образом, хотя точность не может быть 100%, она достаточно высока для практического использования. Если вы заметили крайние неточности, сообщите нам, чтобы мы могли улучшить наши системы.
Так же, как и в отношении точности, легко проверить, действительно ли кластеры похожи, поскольку заголовки представлены для проверки.
Наконец, пока другие истории отображаются в ленте новостей под Подобный контент header, пользователи не упустят важных тонкостей в формулировках заголовков и историй, ведь контент можно проверить напрямую. Поэтому, если вы хотите углубиться в тему, держите Показывать похожий контент в ленте опция включена. Это настоятельно рекомендуется перед принятием инвестиционного или делового решения. В противном случае, если вы просто хотите просмотреть, что происходит сегодня, упустить тонкости в формулировке заголовка не будет проблемой, и вы можете отключить Показывать похожий контент в ленте переключатель.
Создан для масштабируемости и производительности
Подобные истории - это чрезвычайно трудоемкое мероприятие. В дни высокой активности мы можем обрабатывать миллионы единиц контента в конвейере CityFALCON, в то время как даже в более медленное время мы регулярно обрабатываем до миллиона в день. После агрегирования и обработки весь этот контент необходимо сравнить со всем контентом, который мы уже обработали и сохранили за прошедшие дни, чтобы определить сходство. Процесс сравнения векторизует множество измерений каждого фрагмента контента, затем сравнивает контент по размеру и кросс-векторному. В результате возникает ошеломляющая потребность в вычислениях.
Это требование к вычислениям сделало некоторые популярные языки, такие как Java и Python, слишком громоздкими для обработки огромных потоков данных. По этой причине мы написали наш компонент «Группирование похожих историй» на C ++, сильном языке для повышения производительности и низких накладных расходов. Чем меньше накладные расходы, тем быстрее и эффективнее обработка - и в этом сценарии нам требовалось любое преимущество в эффективности, которое мы могли получить. Кроме того, гибкость управления использованием ресурсов в C ++ делает его идеальным для жесткого контроля вычислений и затрат на ресурсы, особенно использования памяти.
После некоторой части исследований и разработок мы создали высокоэффективную версию, которая предоставляет пользователям то, что им нужно, и позволяет контролировать наши затраты на обработку.
По мере масштабирования системы использование C ++ с низкими накладными расходами гарантирует, что масштабируемость не будет скомпрометирована, поэтому все клиенты CityFALCON, от высокопроизводительных пользователей API до пользователей-потребителей с небольшим объемом, обеспечивают плавную и точную доставку контента.
Сократите время исследования сегодня
Мы ожидаем, что большинство пользователей получат пользу от этой функции, поэтому включаем ее по умолчанию. Протестируйте новую функцию на действительно популярных темах, например, на этой список просмотра популярных акций. После этого у вас будет больше времени заниматься бизнесом, побыть с друзьями и семьей или использовать свое время в других целях, а не просматривать практически идентичный контент о ваших инвестициях.
Добавить комментарий