


Этот год был захватывающим с точки зрения новых выпусков, и продукт CityFALCON действительно обретает форму благодаря аналитике, большему количеству источников и большему количеству сервисов, которые появятся в сети в первой половине 2020 года. Многие сервисы и функции API действительно очень мощные, и за ними стояли значительные усилия в области НИОКР. По этой причине для большинства новых функций есть собственные сообщения в блогах, так что вы можете более тщательно их понять. Этот пост просто познакомит вас с тем, чего мы достигли в этом году.
Если вы хотите увидеть, что мы сделали в отношении потребителей в первой половине 2020 года, ознакомьтесь с Сообщение об обновлениях CityFALCON 2020 Retail.
Документы из Лондонской фондовой биржи, Регистрационной палаты, Бюллетеня и др.
Примерно в начале этого года мы начали принимать заявки с Лондонской фондовой биржи (LSE) и Регистрационной палаты в Великобритании. С тех пор мы добавили The Gazette и собираемся добавить документы из SEC в Соединенных Штатах. Мы уже получили данные и настроены в нашей промежуточной среде, но нам нужно еще немного времени, чтобы отправить заявки SEC в производственную среду.
Мы опубликовали полная запись в блоге о выпуске наших документов. На данный момент они доступны только через API, но вскоре мы добавим их на веб-сайт и в мобильные приложения.
NLU извлечение
Еще одна очень ценная функция для предприятий - это наша служба извлечения NLU. Опять же, это гарантировало собственное сообщение в блоге.
Мы построили сервис на протяжении большей части жизни CityFALCON, и мы использовали его внутри для извлечения сущностей из текста. Например, мы алгоритмически извлекаем Amazon из заголовка и отметьте его как компанию для этого фрагмента контента.
В сочетании с нашей иерархической базой данных полученная информация может быть очень полезной. У нас есть тикер Amazon, их номера IRS и SEC, а также структура связанных секторов, отраслей и подотраслей.
Теперь предприятия могут использовать эту службу и структурированные данные о собственном внутреннем контенте, таком как записки, чаты, электронные письма и внутренние отчеты. См. Сообщение в блоге выше для более подробной информации. Мы предоставляем извлечение сущностей NLU как автономную услугу для индексации внутреннего контента, поэтому подписывающимся предприятиям не нужно покупать другие пакеты API, если они им не нужны.
Ниже приведен пример ответа в формате JSON на простое сообщение, отправляемое между двумя сотрудниками, который дает много информации для компаний.
Ответ JSON на неформальное сообщение между двумя сотрудниками«Text»: «вы думаете, что США начнут расследование против Facebook»,
«Lang»: «en»,
«Теги»: [
{
«Начало»: 14,
«Конец»: 16,
«Значение»: «США»,
«Тип»: «местоположение»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Соединенные Штаты Америки»,
«Тип»: «гео_регионы»,
«Метаданные»: {
«Страны»: [
"Соединенные Штаты Америки"
],
«Субконтиненты»: [
«Северная Америка»
],
«Континенты»: [
"Северная Америка"
]
}
}
]
},
{
«Начало»: 51,
«Конец»: 59,
«Value»: «Facebook»,
«Тип»: «компания»,
«Сопоставлено»: правда,
«Сущности»: [
{
«Name»: «Facebook Inc»,
«Тип»: «акции»,
«Метаданные»: {
«Legal_ids»: [
«0201665019_irs-us»,
«0001326801_sec-us»
],
«Тикеры»: [
«FB_US»
],
«Категории»: [
"Социальные медиа"
],
«Подотрасли»: [
«Интернет-услуги и инфраструктура»
],
«Отрасли»: [
«ИТ-услуги»
],
«Секторы»: [
"Технологии",
«Связь»
]
}
}
]
},
{
«Начало»: 22,
«Конец»: 42,
«Value»: «начать расследование»,
«Тип»: «событие»,
«Соответствует»: ложь
}
]
}
Тикеры и юридические номера, полученные из службы NLU, могут быть введены в службу регистрации для автоматизации множества задач. Одна потенциальная внутренняя панель инструментов, которая извлекает объекты, а затем перетекает в извлечение файлов, исследований и новостного контента, может выглядеть следующим образом:
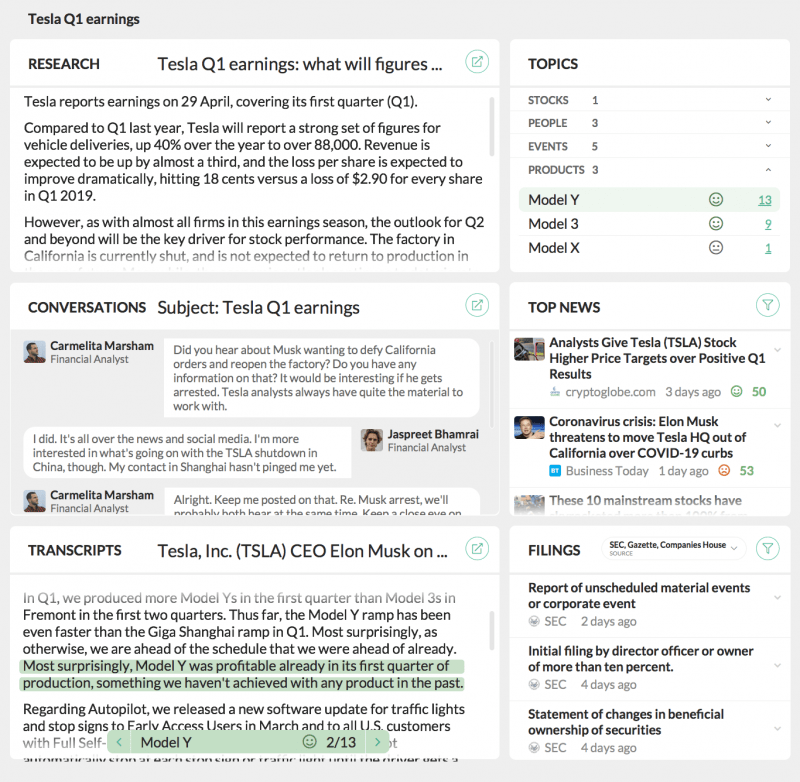
Потенциальное внутреннее приложение для помощи сотрудникам в их исследованиях и работе
Группировка похожих историй на 16 языках
В «Сходных историях» используется расширенное запатентованное машинное обучение для сравнения каждого отдельного фрагмента контента, который мы получаем на предмет схожести, включая новости, твиты и отчеты. Каждый фрагмент контента сравнивается с любым другим фрагментом с использованием 512 измерений, таких как автор и местоположение. Конечно, с более чем 500 измерениями некоторые из них могут показаться странными комбинациями и могут не иметь большого значения для людей, но корреляции, которые могут провести алгоритмы больших данных, могут выявить некоторые тонкие сходства.
После сравнения всего контента группы формируются на основе близости друг к другу в векторном пространстве сравнения сходства. Затем AI выбирает наиболее представителя группы ( центроид), и этот фрагмент контента помечается как основная история, которая возвращается как запись верхнего уровня в JSON. В каждой записи JSON верхнего уровня другой контент в группе подпадает под Similar_content поле этой записи.
В Интернете и на мобильных устройствах это позволяет людям легко пропускать повторяющийся контент или, наоборот, читать разные варианты и ракурсы одного и того же события.
В API эта настройка может привести к лучшей обработке различных углов. CityFALCON уже сгруппировал контент, поэтому вашей компании не нужно исследовать и выполнять эту сложную задачу NLU. Теперь вы можете сосредоточиться на принятии решений, используя эту аналогичную информацию, вместо того, чтобы связывать ресурсы, пытаясь создать технологию NLU - мы уже разработали ее для вас. Если ваше приложение предполагает обслуживание контента для конечных пользователей, вы можете удалить все похожие истории и отображать только самые популярные записи JSON (т. Е. Уникальные истории), так что они выиграют от того же сокращения избыточности.
Более того, алгоритм подобия работает на 16 языках. Один из вариантов использования - уловить нюансы, чтобы двуязычные команды проанализировали и получили представление о мыслительном процессе и потенциальных результатах событий, в зависимости от того, кто что и когда пишет.
Анализ настроений
Это еще одна особенность, которая настолько ценна, что мы написали все сообщение в блоге об анализе настроений.
Анализ настроений - это мощный аналитический инструмент, который использует NLU для оценки контента в зависимости от того, насколько позитивным, негативным или нейтральным является его язык. Наши системы разбивают контент на уровне предложений, поэтому даже одно предложение может иметь несколько связанных оценок тональности (по одной для каждого предложения).
Кроме того, используя нашу службу извлечения сущностей NLU (конечно, внутреннюю), мы можем определить, какая из наших 300 000 сущностей в нашей базе данных связана с рассматриваемым контентом. Затем мы строим совокупные оценки для всех местоположений, людей, компаний, акций, организаций и других типов объектов в базе данных.
Агрегированные группы, такие как Секторы (совокупность всех компаний-участников), также получают свои собственные оценки. Оценки для агрегированных групп являются средневзвешенными, поэтому, хотя CityFALCON входит в технический сектор вместе с Microsoft и IBM, эти два обычно имеют гораздо больший вес, чем CityFALCON, потому что они привлекают гораздо больше внимания СМИ.
Упрощенный обзор системы может выглядеть так:
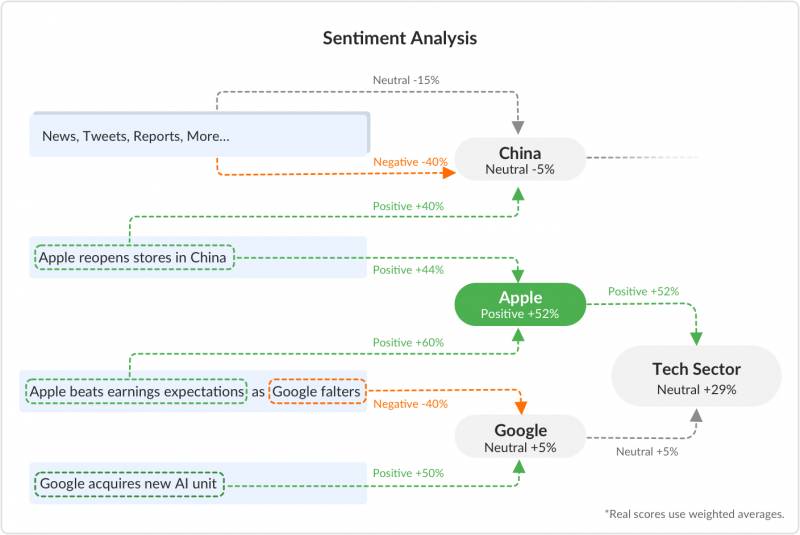
Упрощенный обзор связей анализа тональности
Через API эти данные передаются вместе с сущностями и контентом (новостями). Красиво отформатированный (красиво напечатанный) ответ JSON с тональностью может выглядеть так:
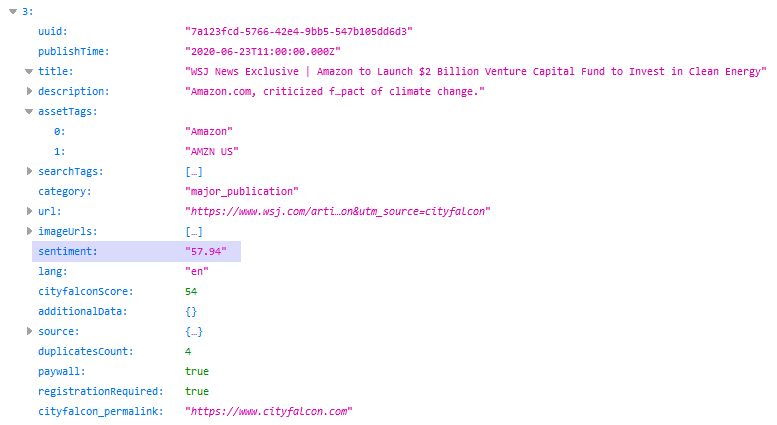
Добавление поля юридического идентификатора для поиска
Раньше API принимал только активы, тикеры, и full_tickers в качестве полей ввода для поиска компаний, людей и других объектов запрашиваемой информации. Теперь пользователи API могут искать по legal_id, тоже. Это делает интеграцию более стандартизированной и точной. Более того, легче ориентироваться на частные компании, у которых нет тикеров. Например, Revolut в Великобритании - очень популярная компания для просмотра, но у нее нет стандартного тикера для ее идентификации. С legal_id поле, теперь пользователи API могут настраивать таргетинг 08804411_companieshouse-gb для получения информации о Revolut.
Увидеть База знаний для получения дополнительных руководств и объяснений или ознакомьтесь с документация чтобы попробовать в песочнице.
Персональный доступ к API
Мы также открыли API для личного использования. Мы заметили интерес со стороны разработчиков и частных лиц, которые хотели создавать свои собственные финансовые и бизнес-приложения с использованием наших данных, но не смогли приобрести полные подписки на API.
Теперь люди могут использовать API для совершения до 10 000 звонков в месяц и получения данных истории, названия, описания и оценки CityFALCON.
Персональная подписка начинается с $20 в месяц для академических, медицинских и некоммерческих пользователей или $40 в месяц для всех остальных. Скоро появится версия Premium, которая предлагает больше функций и более высокий лимит звонков.
Подробности в специальный пост в блоге о доступе к персональному API.
Заинтересованные стороны и вторая половина
Пока что в этом году мы выпустили довольно много основных функций для API, и мы уверены в том, что наша компания выпустит больше в будущем. Мы гордимся тем, чего мы достигли на сегодняшний день, и рады пожинать плоды многолетних исследований и разработок в области науки о данных, инфраструктуры и управления финансовыми данными.
Мы постоянно добавляем новые источники контента и продолжаем R&D проект на Мальте чтобы расширить наш языковой охват как с точки зрения содержания, так и с точки зрения приложений машинного обучения. Дополнительные услуги машинного обучения для внутренних данных не за горами.
Если вас интересуют какие-либо службы API, сделайте Связаться с нами для консультации и демонстрации. Чем лучше мы знаем ваш вариант использования и ситуацию, тем лучший продукт мы можем вам предоставить.
Добавить комментарий